# NeuralNeworkRuntime
## Overview
Provides APIs for accelerating the Neural Network Runtime (NNRt) model inference.
**Since**: 9
## Summary
### File
| Name| Description|
| -------- | -------- |
| [neural_network_core.h](neural__network__core_8h.md) | Defines APIs for the Neural Network Core module. The AI inference framework uses the native interfaces provided by Neural Network Core to build models and perform inference and computing on acceleration device.|
| [neural_network_runtime.h](neural__network__runtime_8h.md) | Defines APIs for NNRt. The AI inference framework uses the native APIs provided by the NNRt to construct and build models.|
| [neural_network_runtime_type.h](neural__network__runtime__type_8h.md) | Defines the structure and enums for NNRt.|
### Structs
| Name| Description|
| -------- | -------- |
| struct [OH_NN_UInt32Array](_o_h___n_n___u_int32_array.md) | Used to store a 32-bit unsigned integer array.|
| struct [OH_NN_QuantParam](_o_h___n_n___quant_param.md) | Used to define the quantization information.|
| struct [OH_NN_Tensor](_o_h___n_n___tensor.md) | Used to define the tensor structure.|
| struct [OH_NN_Memory](_o_h___n_n___memory.md) | Used to define the memory structure.|
### Types
| Name| Description|
| -------- | -------- |
| typedef struct [OH_NNModel](#oh_nnmodel) [OH_NNModel](#oh_nnmodel) | Model handle.|
| typedef struct [OH_NNCompilation](#oh_nncompilation) [OH_NNCompilation](#oh_nncompilation) | Compiler handle.|
| typedef struct [OH_NNExecutor](#oh_nnexecutor) [OH_NNExecutor](#oh_nnexecutor) | Executor handle.|
| typedef struct [NN_QuantParam](#nn_quantparam) [NN_QuantParam](#nn_quantparam) | Quantization parameter handle.|
| typedef struct [NN_TensorDesc](#nn_tensordesc) [NN_TensorDesc](#nn_tensordesc) | Tensor description handle.|
| typedef struct [NN_Tensor](#nn_tensor) [NN_Tensor](#nn_tensor) | Tensor handle.|
| typedef enum [OH_NN_PerformanceMode](#oh_nn_performancemode) [OH_NN_PerformanceMode](#oh_nn_performancemode) | Performance modes of the device.|
| typedef enum [OH_NN_Priority](#oh_nn_priority) [OH_NN_Priority](#oh_nn_priority) | Priorities of a model inference task.|
| typedef enum [OH_NN_ReturnCode](#oh_nn_returncode) [OH_NN_ReturnCode](#oh_nn_returncode) | Error codes for NNRt.|
| typedef void(\* [NN_OnRunDone](#nn_onrundone)) (void \*userData, [OH_NN_ReturnCode](#oh_nn_returncode) errCode, void \*outputTensor[], int32_t outputCount) | Handle of the callback processing function invoked when the asynchronous inference ends.|
| typedef void(\* [NN_OnServiceDied](#nn_onservicedied)) (void \*userData) | Handle of the callback processing function invoked when the device driver service terminates unexpectedly during asynchronous inference.|
| typedef enum [OH_NN_FuseType](#oh_nn_fusetype) [OH_NN_FuseType](#oh_nn_fusetype) | Activation function types in the fusion operator for NNRt.|
| typedef enum [OH_NN_Format](#oh_nn_format) [OH_NN_Format](#oh_nn_format) | Formats of tensor data.|
| typedef enum [OH_NN_DeviceType](#oh_nn_devicetype) [OH_NN_DeviceType](#oh_nn_devicetype) | Device types supported by NNRt.|
| typedef enum [OH_NN_DataType](#oh_nn_datatype) [OH_NN_DataType](#oh_nn_datatype) | Data types supported by NNRt.|
| typedef enum [OH_NN_OperationType](#oh_nn_operationtype) [OH_NN_OperationType](#oh_nn_operationtype) | Operator types supported by NNRt.|
| typedef enum [OH_NN_TensorType](#oh_nn_tensortype) [OH_NN_TensorType](#oh_nn_tensortype) | Tensor types.|
| typedef struct [OH_NN_UInt32Array](_o_h___n_n___u_int32_array.md) [OH_NN_UInt32Array](#oh_nn_uint32array) | Used to store a 32-bit unsigned integer array.|
| typedef struct [OH_NN_QuantParam](_o_h___n_n___quant_param.md) [OH_NN_QuantParam](#oh_nn_quantparam) | Used to define the quantization information.|
| typedef struct [OH_NN_Tensor](_o_h___n_n___tensor.md) [OH_NN_Tensor](#oh_nn_tensor) | Used to define the tensor structure.|
| typedef struct [OH_NN_Memory](_o_h___n_n___memory.md) [OH_NN_Memory](#oh_nn_memory) | Used to define the memory structure.|
### Enums
| Name| Description|
| -------- | -------- |
| [OH_NN_PerformanceMode](#oh_nn_performancemode) {
OH_NN_PERFORMANCE_NONE = 0, OH_NN_PERFORMANCE_LOW = 1, OH_NN_PERFORMANCE_MEDIUM = 2, OH_NN_PERFORMANCE_HIGH = 3,
OH_NN_PERFORMANCE_EXTREME = 4
} | Performance modes of the device.|
| [OH_NN_Priority](#oh_nn_priority) { OH_NN_PRIORITY_NONE = 0, OH_NN_PRIORITY_LOW = 1, OH_NN_PRIORITY_MEDIUM = 2, OH_NN_PRIORITY_HIGH = 3 } | Priorities of a model inference task.|
| [OH_NN_ReturnCode](#oh_nn_returncode) {
OH_NN_SUCCESS = 0, OH_NN_FAILED = 1, OH_NN_INVALID_PARAMETER = 2, OH_NN_MEMORY_ERROR = 3,
OH_NN_OPERATION_FORBIDDEN = 4, OH_NN_NULL_PTR = 5, OH_NN_INVALID_FILE = 6, OH_NN_UNAVALIDABLE_DEVICE = 7,
OH_NN_INVALID_PATH = 8, OH_NN_TIMEOUT = 9, OH_NN_UNSUPPORTED = 10, OH_NN_CONNECTION_EXCEPTION = 11,
OH_NN_SAVE_CACHE_EXCEPTION = 12, OH_NN_DYNAMIC_SHAPE = 13, OH_NN_UNAVAILABLE_DEVICE = 14
} | Error codes for NNRt.|
| [OH_NN_FuseType](#oh_nn_fusetype) : int8_t { OH_NN_FUSED_NONE = 0, OH_NN_FUSED_RELU = 1, OH_NN_FUSED_RELU6 = 2 } | Activation function types in the fusion operator for NNRt.|
| [OH_NN_Format](#oh_nn_format) { OH_NN_FORMAT_NONE = 0, OH_NN_FORMAT_NCHW = 1, OH_NN_FORMAT_NHWC = 2, OH_NN_FORMAT_ND = 3 } | Formats of tensor data.|
| [OH_NN_DeviceType](#oh_nn_devicetype) { OH_NN_OTHERS = 0, OH_NN_CPU = 1, OH_NN_GPU = 2, OH_NN_ACCELERATOR = 3 } | Device types supported by NNRt.|
| [OH_NN_DataType](#oh_nn_datatype) {
OH_NN_UNKNOWN = 0, OH_NN_BOOL = 1, OH_NN_INT8 = 2, OH_NN_INT16 = 3,
OH_NN_INT32 = 4, OH_NN_INT64 = 5, OH_NN_UINT8 = 6, OH_NN_UINT16 = 7,
OH_NN_UINT32 = 8, OH_NN_UINT64 = 9, OH_NN_FLOAT16 = 10, OH_NN_FLOAT32 = 11,
OH_NN_FLOAT64 = 12
} | Data types supported by NNRt.|
| [OH_NN_OperationType](#oh_nn_operationtype) {
OH_NN_OPS_ADD = 1, OH_NN_OPS_AVG_POOL = 2, OH_NN_OPS_BATCH_NORM = 3, OH_NN_OPS_BATCH_TO_SPACE_ND = 4,
OH_NN_OPS_BIAS_ADD = 5, OH_NN_OPS_CAST = 6, OH_NN_OPS_CONCAT = 7, OH_NN_OPS_CONV2D = 8,
OH_NN_OPS_CONV2D_TRANSPOSE = 9, OH_NN_OPS_DEPTHWISE_CONV2D_NATIVE = 10, OH_NN_OPS_DIV = 11, OH_NN_OPS_ELTWISE = 12,
OH_NN_OPS_EXPAND_DIMS = 13, OH_NN_OPS_FILL = 14, OH_NN_OPS_FULL_CONNECTION = 15, OH_NN_OPS_GATHER = 16,
OH_NN_OPS_HSWISH = 17, OH_NN_OPS_LESS_EQUAL = 18, OH_NN_OPS_MATMUL = 19, OH_NN_OPS_MAXIMUM = 20,
OH_NN_OPS_MAX_POOL = 21, OH_NN_OPS_MUL = 22, OH_NN_OPS_ONE_HOT = 23, OH_NN_OPS_PAD = 24,
OH_NN_OPS_POW = 25, OH_NN_OPS_SCALE = 26, OH_NN_OPS_SHAPE = 27, OH_NN_OPS_SIGMOID = 28,
OH_NN_OPS_SLICE = 29, OH_NN_OPS_SOFTMAX = 30, OH_NN_OPS_SPACE_TO_BATCH_ND = 31, OH_NN_OPS_SPLIT = 32,
OH_NN_OPS_SQRT = 33, OH_NN_OPS_SQUARED_DIFFERENCE = 34, OH_NN_OPS_SQUEEZE = 35, OH_NN_OPS_STACK = 36,
OH_NN_OPS_STRIDED_SLICE = 37, OH_NN_OPS_SUB = 38, OH_NN_OPS_TANH = 39, OH_NN_OPS_TILE = 40,
OH_NN_OPS_TRANSPOSE = 41, OH_NN_OPS_REDUCE_MEAN = 42, OH_NN_OPS_RESIZE_BILINEAR = 43, OH_NN_OPS_RSQRT = 44,
OH_NN_OPS_RESHAPE = 45, OH_NN_OPS_PRELU = 46, OH_NN_OPS_RELU = 47, OH_NN_OPS_RELU6 = 48,
OH_NN_OPS_LAYER_NORM = 49, OH_NN_OPS_REDUCE_PROD = 50, OH_NN_OPS_REDUCE_ALL = 51, OH_NN_OPS_QUANT_DTYPE_CAST = 52,
OH_NN_OPS_TOP_K = 53, OH_NN_OPS_ARG_MAX = 54, OH_NN_OPS_UNSQUEEZE = 55, OH_NN_OPS_GELU = 56,
OH_NN_OPS_UNSTACK = 57, OH_NN_OPS_ABS = 58, OH_NN_OPS_ERF = 59, OH_NN_OPS_EXP = 60,
OH_NN_OPS_LESS = 61, OH_NN_OPS_SELECT = 62, OH_NN_OPS_SQUARE = 63, OH_NN_OPS_FLATTEN = 64,
OH_NN_OPS_DEPTH_TO_SPACE = 65, OH_NN_OPS_RANGE = 66, OH_NN_OPS_INSTANCE_NORM = 67, OH_NN_OPS_CONSTANT_OF_SHAPE = 68,
OH_NN_OPS_BROADCAST_TO = 69, OH_NN_OPS_EQUAL = 70, OH_NN_OPS_GREATER = 71, OH_NN_OPS_NOT_EQUAL = 72,
OH_NN_OPS_GREATER_EQUAL = 73, OH_NN_OPS_LEAKY_RELU = 74, OH_NN_OPS_LSTM = 75, OH_NN_OPS_CLIP = 76,
OH_NN_OPS_ALL = 77, OH_NN_OPS_ASSERT = 78, OH_NN_OPS_COS = 79, OH_NN_OPS_LOG = 80,
OH_NN_OPS_LOGICAL_AND = 81, OH_NN_OPS_LOGICAL_NOT = 82, OH_NN_OPS_MOD = 83, OH_NN_OPS_NEG = 84,
OH_NN_OPS_RECIPROCAL = 85, OH_NN_OPS_SIN = 86, OH_NN_OPS_WHERE = 87, OH_NN_OPS_SPARSE_TO_DENSE = 88,
OH_NN_OPS_LOGICAL_OR = 89, OH_NN_OPS_CEIL = 90, OH_NN_OPS_CROP = 91, OH_NN_OPS_DETECTION_POST_PROCESS = 92,
OH_NN_OPS_FLOOR = 93, OH_NN_OPS_L2_NORMALIZE = 94, OH_NN_OPS_LOG_SOFTMAX = 95, OH_NN_OPS_LRN = 96,
OH_NN_OPS_MINIMUM = 97, OH_NN_OPS_RANK = 98, OH_NN_OPS_REDUCE_MAX = 99, OH_NN_OPS_REDUCE_MIN = 100,
OH_NN_OPS_REDUCE_SUM = 101, OH_NN_OPS_ROUND = 102, OH_NN_OPS_SCATTER_ND = 103, OH_NN_OPS_SPACE_TO_DEPTH = 104,
OH_NN_OPS_SWISH = 105, OH_NN_OPS_REDUCE_L2 = 106, OH_NN_OPS_HARD_SIGMOID = 107, OH_NN_OPS_GATHER_ND = 108
} | Operator types supported by NNRt.|
| [OH_NN_TensorType](#oh_nn_tensortype) {
OH_NN_TENSOR = 0, OH_NN_ADD_ACTIVATIONTYPE = 1, OH_NN_AVG_POOL_KERNEL_SIZE = 2, OH_NN_AVG_POOL_STRIDE = 3,
OH_NN_AVG_POOL_PAD_MODE = 4, OH_NN_AVG_POOL_PAD = 5, OH_NN_AVG_POOL_ACTIVATION_TYPE = 6, OH_NN_BATCH_NORM_EPSILON = 7,
OH_NN_BATCH_TO_SPACE_ND_BLOCKSIZE = 8, OH_NN_BATCH_TO_SPACE_ND_CROPS = 9, OH_NN_CONCAT_AXIS = 10, OH_NN_CONV2D_STRIDES = 11,
OH_NN_CONV2D_PAD = 12, OH_NN_CONV2D_DILATION = 13, OH_NN_CONV2D_PAD_MODE = 14, OH_NN_CONV2D_ACTIVATION_TYPE = 15,
OH_NN_CONV2D_GROUP = 16, OH_NN_CONV2D_TRANSPOSE_STRIDES = 17, OH_NN_CONV2D_TRANSPOSE_PAD = 18, OH_NN_CONV2D_TRANSPOSE_DILATION = 19,
OH_NN_CONV2D_TRANSPOSE_OUTPUT_PADDINGS = 20, OH_NN_CONV2D_TRANSPOSE_PAD_MODE = 21, OH_NN_CONV2D_TRANSPOSE_ACTIVATION_TYPE = 22, OH_NN_CONV2D_TRANSPOSE_GROUP = 23,
OH_NN_DEPTHWISE_CONV2D_NATIVE_STRIDES = 24, OH_NN_DEPTHWISE_CONV2D_NATIVE_PAD = 25, OH_NN_DEPTHWISE_CONV2D_NATIVE_DILATION = 26, OH_NN_DEPTHWISE_CONV2D_NATIVE_PAD_MODE = 27,
OH_NN_DEPTHWISE_CONV2D_NATIVE_ACTIVATION_TYPE = 28, OH_NN_DIV_ACTIVATIONTYPE = 29, OH_NN_ELTWISE_MODE = 30, OH_NN_FULL_CONNECTION_AXIS = 31,
OH_NN_FULL_CONNECTION_ACTIVATIONTYPE = 32, OH_NN_MATMUL_TRANSPOSE_A = 33, OH_NN_MATMUL_TRANSPOSE_B = 34, OH_NN_MATMUL_ACTIVATION_TYPE = 35,
OH_NN_MAX_POOL_KERNEL_SIZE = 36, OH_NN_MAX_POOL_STRIDE = 37, OH_NN_MAX_POOL_PAD_MODE = 38, OH_NN_MAX_POOL_PAD = 39,
OH_NN_MAX_POOL_ACTIVATION_TYPE = 40, OH_NN_MUL_ACTIVATION_TYPE = 41, OH_NN_ONE_HOT_AXIS = 42, OH_NN_PAD_CONSTANT_VALUE = 43,
OH_NN_SCALE_ACTIVATIONTYPE = 44, OH_NN_SCALE_AXIS = 45, OH_NN_SOFTMAX_AXIS = 46, OH_NN_SPACE_TO_BATCH_ND_BLOCK_SHAPE = 47,
OH_NN_SPACE_TO_BATCH_ND_PADDINGS = 48, OH_NN_SPLIT_AXIS = 49, OH_NN_SPLIT_OUTPUT_NUM = 50, OH_NN_SPLIT_SIZE_SPLITS = 51,
OH_NN_SQUEEZE_AXIS = 52, OH_NN_STACK_AXIS = 53, OH_NN_STRIDED_SLICE_BEGIN_MASK = 54, OH_NN_STRIDED_SLICE_END_MASK = 55,
OH_NN_STRIDED_SLICE_ELLIPSIS_MASK = 56, OH_NN_STRIDED_SLICE_NEW_AXIS_MASK = 57, OH_NN_STRIDED_SLICE_SHRINK_AXIS_MASK = 58, OH_NN_SUB_ACTIVATIONTYPE = 59,
OH_NN_REDUCE_MEAN_KEEP_DIMS = 60, OH_NN_RESIZE_BILINEAR_NEW_HEIGHT = 61, OH_NN_RESIZE_BILINEAR_NEW_WIDTH = 62, OH_NN_RESIZE_BILINEAR_PRESERVE_ASPECT_RATIO = 63,
OH_NN_RESIZE_BILINEAR_COORDINATE_TRANSFORM_MODE = 64, OH_NN_RESIZE_BILINEAR_EXCLUDE_OUTSIDE = 65, OH_NN_LAYER_NORM_BEGIN_NORM_AXIS = 66, OH_NN_LAYER_NORM_EPSILON = 67,
OH_NN_LAYER_NORM_BEGIN_PARAM_AXIS = 68, OH_NN_LAYER_NORM_ELEMENTWISE_AFFINE = 69, OH_NN_REDUCE_PROD_KEEP_DIMS = 70, OH_NN_REDUCE_ALL_KEEP_DIMS = 71,
OH_NN_QUANT_DTYPE_CAST_SRC_T = 72, OH_NN_QUANT_DTYPE_CAST_DST_T = 73, OH_NN_TOP_K_SORTED = 74, OH_NN_ARG_MAX_AXIS = 75,
OH_NN_ARG_MAX_KEEPDIMS = 76, OH_NN_UNSQUEEZE_AXIS = 77, OH_NN_UNSTACK_AXIS = 78, OH_NN_FLATTEN_AXIS = 79,
OH_NN_DEPTH_TO_SPACE_BLOCK_SIZE = 80, OH_NN_DEPTH_TO_SPACE_MODE = 81, OH_NN_RANGE_START = 82, OH_NN_RANGE_LIMIT = 83,
OH_NN_RANGE_DELTA = 84, OH_NN_CONSTANT_OF_SHAPE_DATA_TYPE = 85, OH_NN_CONSTANT_OF_SHAPE_VALUE = 86, OH_NN_BROADCAST_TO_SHAPE = 87,
OH_NN_INSTANCE_NORM_EPSILON = 88, OH_NN_EXP_BASE = 89, OH_NN_EXP_SCALE = 90, OH_NN_EXP_SHIFT = 91,
OH_NN_LEAKY_RELU_NEGATIVE_SLOPE = 92, OH_NN_LSTM_BIDIRECTIONAL = 93, OH_NN_LSTM_HAS_BIAS = 94, OH_NN_LSTM_INPUT_SIZE = 95,
OH_NN_LSTM_HIDDEN_SIZE = 96, OH_NN_LSTM_NUM_LAYERS = 97, OH_NN_LSTM_NUM_DIRECTIONS = 98, OH_NN_LSTM_DROPOUT = 99,
OH_NN_LSTM_ZONEOUT_CELL = 100, OH_NN_LSTM_ZONEOUT_HIDDEN = 101, OH_NN_LSTM_PROJ_SIZE = 102, OH_NN_CLIP_MAX = 103,
OH_NN_CLIP_MIN = 104, OH_NN_ALL_KEEP_DIMS = 105, OH_NN_ASSERT_SUMMARIZE = 106, OH_NN_POW_SCALE = 107,
OH_NN_POW_SHIFT = 108, OH_NN_AVG_POOL_ROUND_MODE = 109, OH_NN_AVG_POOL_GLOBAL = 110, OH_NN_FULL_CONNECTION_HAS_BIAS = 111,
OH_NN_FULL_CONNECTION_USE_AXIS = 112, OH_NN_GELU_APPROXIMATE = 113, OH_NN_MAX_POOL_ROUND_MODE = 114, OH_NN_MAX_POOL_GLOBAL = 115,
OH_NN_PAD_PADDING_MODE = 116, OH_NN_REDUCE_MEAN_REDUCE_TO_END = 117, OH_NN_REDUCE_MEAN_COEFF = 118, OH_NN_REDUCE_PROD_REDUCE_TO_END = 119,
OH_NN_REDUCE_PROD_COEFF = 120, OH_NN_REDUCE_ALL_REDUCE_TO_END = 121, OH_NN_REDUCE_ALL_COEFF = 122, OH_NN_TOP_K_AXIS = 123,
OH_NN_ARG_MAX_TOP_K = 124, OH_NN_ARG_MAX_OUT_MAX_VALUE = 125, OH_NN_QUANT_DTYPE_CAST_AXIS = 126, OH_NN_SLICE_AXES = 127,
OH_NN_TILE_DIMS = 128, OH_NN_CROP_AXIS = 129, OH_NN_CROP_OFFSET = 130, OH_NN_DETECTION_POST_PROCESS_INPUT_SIZE = 131,
OH_NN_DETECTION_POST_PROCESS_SCALE = 132, OH_NN_DETECTION_POST_PROCESS_NMS_IOU_THRESHOLD = 133, OH_NN_DETECTION_POST_PROCESS_NMS_SCORE_THRESHOLD = 134, OH_NN_DETECTION_POST_PROCESS_MAX_DETECTIONS = 135,
OH_NN_DETECTION_POST_PROCESS_DETECTIONS_PER_CLASS = 136, OH_NN_DETECTION_POST_PROCESS_MAX_CLASSES_PER_DETECTION = 137, OH_NN_DETECTION_POST_PROCESS_NUM_CLASSES = 138, OH_NN_DETECTION_POST_PROCESS_USE_REGULAR_NMS = 139,
OH_NN_DETECTION_POST_PROCESS_OUT_QUANTIZED = 140, OH_NN_L2_NORMALIZE_AXIS = 141, OH_NN_L2_NORMALIZE_EPSILON = 142, OH_NN_L2_NORMALIZE_ACTIVATION_TYPE = 143,
OH_NN_LOG_SOFTMAX_AXIS = 144, OH_NN_LRN_DEPTH_RADIUS = 145, OH_NN_LRN_BIAS = 146, OH_NN_LRN_ALPHA = 147,
OH_NN_LRN_BETA = 148, OH_NN_LRN_NORM_REGION = 149, OH_NN_SPACE_TO_DEPTH_BLOCK_SIZE = 150, OH_NN_REDUCE_MAX_KEEP_DIMS = 151,
OH_NN_REDUCE_MAX_REDUCE_TO_END = 152, OH_NN_REDUCE_MAX_COEFF = 153, OH_NN_REDUCE_MIN_KEEP_DIMS = 154, OH_NN_REDUCE_MIN_REDUCE_TO_END = 155,
OH_NN_REDUCE_MIN_COEFF = 156, OH_NN_REDUCE_SUM_KEEP_DIMS = 157, OH_NN_REDUCE_SUM_REDUCE_TO_END = 158, OH_NN_REDUCE_SUM_COEFF = 159,
OH_NN_REDUCE_L2_KEEP_DIMS = 160, OH_NN_REDUCE_L2_REDUCE_TO_END = 161, OH_NN_REDUCE_L2_COEFF = 162
} | Tensor types.|
### Functions
| Name| Description|
| -------- | -------- |
| [OH_NNCompilation](#oh_nncompilation) \* [OH_NNCompilation_Construct](#oh_nncompilation_construct) (const [OH_NNModel](#oh_nnmodel) \*model) | Creates a model building instance of the [OH_NNCompilation](#oh_nncompilation) type.|
| [OH_NNCompilation](#oh_nncompilation) \* [OH_NNCompilation_ConstructWithOfflineModelFile](#oh_nncompilation_constructwithofflinemodelfile) (const char \*modelPath) | Creates a model building instance based on an offline model file.|
| [OH_NNCompilation](#oh_nncompilation) \* [OH_NNCompilation_ConstructWithOfflineModelBuffer](#oh_nncompilation_constructwithofflinemodelbuffer) (const void \*modelBuffer, size_t modelSize) | Creates a model building instance based on the offline model buffer.|
| [OH_NNCompilation](#oh_nncompilation) \* [OH_NNCompilation_ConstructForCache](#oh_nncompilation_constructforcache) () | Creates an empty model building instance for later recovery from the model cache.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNCompilation_ExportCacheToBuffer](#oh_nncompilation_exportcachetobuffer) ([OH_NNCompilation](#oh_nncompilation) \*compilation, const void \*buffer, size_t length, size_t \*modelSize) | Writes the model cache to the specified buffer.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNCompilation_ImportCacheFromBuffer](#oh_nncompilation_importcachefrombuffer) ([OH_NNCompilation](#oh_nncompilation) \*compilation, const void \*buffer, size_t modelSize) | Reads the model cache from the specified buffer.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNCompilation_AddExtensionConfig](#oh_nncompilation_addextensionconfig) ([OH_NNCompilation](#oh_nncompilation) \*compilation, const char \*configName, const void \*configValue, const size_t configValueSize) | Adds extended configurations for custom device attributes.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNCompilation_SetDevice](#oh_nncompilation_setdevice) ([OH_NNCompilation](#oh_nncompilation) \*compilation, size_t deviceID) | Sets the device for model building and computing.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNCompilation_SetCache](#oh_nncompilation_setcache) ([OH_NNCompilation](#oh_nncompilation) \*compilation, const char \*cachePath, uint32_t version) | Sets the cache directory and version for model building.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNCompilation_SetPerformanceMode](#oh_nncompilation_setperformancemode) ([OH_NNCompilation](#oh_nncompilation) \*compilation, [OH_NN_PerformanceMode](#oh_nn_performancemode) performanceMode) | Sets the performance mode for model computing.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNCompilation_SetPriority](#oh_nncompilation_setpriority) ([OH_NNCompilation](#oh_nncompilation) \*compilation, [OH_NN_Priority](#oh_nn_priority) priority) | Sets the priority for model computing.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNCompilation_EnableFloat16](#oh_nncompilation_enablefloat16) ([OH_NNCompilation](#oh_nncompilation) \*compilation, bool enableFloat16) | Enables float16 for computing.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNCompilation_Build](#oh_nncompilation_build) ([OH_NNCompilation](#oh_nncompilation) \*compilation) | Performs model building.|
| void [OH_NNCompilation_Destroy](#oh_nncompilation_destroy) ([OH_NNCompilation](#oh_nncompilation) \*\*compilation) | Destroys a model building instance of the [OH_NNCompilation](#oh_nncompilation) type.|
| [NN_TensorDesc](#nn_tensordesc) \* [OH_NNTensorDesc_Create](#oh_nntensordesc_create) () | Creates an [NN_TensorDesc](#nn_tensordesc) instance.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNTensorDesc_Destroy](#oh_nntensordesc_destroy) ([NN_TensorDesc](#nn_tensordesc) \*\*tensorDesc) | Releases an [NN_TensorDesc](#nn_tensordesc) instance.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNTensorDesc_SetName](#oh_nntensordesc_setname) ([NN_TensorDesc](#nn_tensordesc) \*tensorDesc, const char \*name) | Sets the name of an [NN_TensorDesc](#nn_tensordesc) instance.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNTensorDesc_GetName](#oh_nntensordesc_getname) (const [NN_TensorDesc](#nn_tensordesc) \*tensorDesc, const char \*\*name) | Obtains the name of an [NN_TensorDesc](#nn_tensordesc) instance.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNTensorDesc_SetDataType](#oh_nntensordesc_setdatatype) ([NN_TensorDesc](#nn_tensordesc) \*tensorDesc, [OH_NN_DataType](#oh_nn_datatype) dataType) | Sets the data type of an [NN_TensorDesc](#nn_tensordesc) instance.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNTensorDesc_GetDataType](#oh_nntensordesc_getdatatype) (const [NN_TensorDesc](#nn_tensordesc) \*tensorDesc, [OH_NN_DataType](#oh_nn_datatype) \*dataType) | Obtains the data type of an [NN_TensorDesc](#nn_tensordesc) instance.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNTensorDesc_SetShape](#oh_nntensordesc_setshape) ([NN_TensorDesc](#nn_tensordesc) \*tensorDesc, const int32_t \*shape, size_t shapeLength) | Sets the data shape of an [NN_TensorDesc](#nn_tensordesc) instance.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNTensorDesc_GetShape](#oh_nntensordesc_getshape) (const [NN_TensorDesc](#nn_tensordesc) \*tensorDesc, int32_t \*\*shape, size_t \*shapeLength) | Obtains the shape of an [NN_TensorDesc](#nn_tensordesc) instance.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNTensorDesc_SetFormat](#oh_nntensordesc_setformat) ([NN_TensorDesc](#nn_tensordesc) \*tensorDesc, [OH_NN_Format](#oh_nn_format) format) | Sets the data format of an [NN_TensorDesc](#nn_tensordesc) instance.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNTensorDesc_GetFormat](#oh_nntensordesc_getformat) (const [NN_TensorDesc](#nn_tensordesc) \*tensorDesc, [OH_NN_Format](#oh_nn_format) \*format) | Obtains the data format of an [NN_TensorDesc](#nn_tensordesc) instance.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNTensorDesc_GetElementCount](#oh_nntensordesc_getelementcount) (const [NN_TensorDesc](#nn_tensordesc) \*tensorDesc, size_t \*elementCount) | Obtains the number of elements in an [NN_TensorDesc](#nn_tensordesc) instance.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNTensorDesc_GetByteSize](#oh_nntensordesc_getbytesize) (const [NN_TensorDesc](#nn_tensordesc) \*tensorDesc, size_t \*byteSize) | Obtains the number of bytes occupied by the tensor data obtained through calculation based on the shape and data type of an [NN_TensorDesc](#nn_tensordesc) instance.|
| [NN_Tensor](#nn_tensor) \* [OH_NNTensor_Create](#oh_nntensor_create) (size_t deviceID, [NN_TensorDesc](#nn_tensordesc) \*tensorDesc) | Creates an [NN_Tensor](#nn_tensor) instance from [NN_TensorDesc](#nn_tensordesc).|
| [NN_Tensor](#nn_tensor) \* [OH_NNTensor_CreateWithSize](#oh_nntensor_createwithsize) (size_t deviceID, [NN_TensorDesc](#nn_tensordesc) \*tensorDesc, size_t size) | Creates an [NN_Tensor](#nn_tensor) instance based on the specified memory size and [NN_TensorDesc](#nn_tensordesc) instance.|
| [NN_Tensor](#nn_tensor) \* [OH_NNTensor_CreateWithFd](#oh_nntensor_createwithfd) (size_t deviceID, [NN_TensorDesc](#nn_tensordesc) \*tensorDesc, int fd, size_t size, size_t offset) | Creates an {\@Link NN_Tensor} instance based on the specified file descriptor of the shared memory and [NN_TensorDesc](#nn_tensordesc) instance.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNTensor_Destroy](#oh_nntensor_destroy) ([NN_Tensor](#nn_tensor) \*\*tensor) | Destroys an [NN_Tensor](#nn_tensor) instance.|
| [NN_TensorDesc](#nn_tensordesc) \* [OH_NNTensor_GetTensorDesc](#oh_nntensor_gettensordesc) (const [NN_Tensor](#nn_tensor) \*tensor) | Obtains an [NN_TensorDesc](#nn_tensordesc) instance of [NN_Tensor](#nn_tensor).|
| void \* [OH_NNTensor_GetDataBuffer](#oh_nntensor_getdatabuffer) (const [NN_Tensor](#nn_tensor) \*tensor) | Obtains the memory address of [NN_Tensor](#nn_tensor) data.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNTensor_GetFd](#oh_nntensor_getfd) (const [NN_Tensor](#nn_tensor) \*tensor, int \*fd) | Obtains the file descriptor of the shared memory where [NN_Tensor](#nn_tensor) data is stored.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNTensor_GetSize](#oh_nntensor_getsize) (const [NN_Tensor](#nn_tensor) \*tensor, size_t \*size) | Obtains the size of the shared memory where the [NN_Tensor](#nn_tensor) data is stored.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNTensor_GetOffset](#oh_nntensor_getoffset) (const [NN_Tensor](#nn_tensor) \*tensor, size_t \*offset) | Obtains the offset of [NN_Tensor](#nn_tensor) data in the shared memory.|
| [OH_NNExecutor](#oh_nnexecutor) \* [OH_NNExecutor_Construct](#oh_nnexecutor_construct) ([OH_NNCompilation](#oh_nncompilation) \*compilation) | Creates an [OH_NNExecutor](#oh_nnexecutor) instance.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNExecutor_GetOutputShape](#oh_nnexecutor_getoutputshape) ([OH_NNExecutor](#oh_nnexecutor) \*executor, uint32_t outputIndex, int32_t \*\*shape, uint32_t \*shapeLength) | Obtains the dimension information about the output tensor.|
| void [OH_NNExecutor_Destroy](#oh_nnexecutor_destroy) ([OH_NNExecutor](#oh_nnexecutor) \*\*executor) | Destroys an executor instance to release the memory occupied by it.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNExecutor_GetInputCount](#oh_nnexecutor_getinputcount) (const [OH_NNExecutor](#oh_nnexecutor) \*executor, size_t \*inputCount) | Obtains the number of input tensors.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNExecutor_GetOutputCount](#oh_nnexecutor_getoutputcount) (const [OH_NNExecutor](#oh_nnexecutor) \*executor, size_t \*outputCount) | Obtains the number of output tensors.|
| [NN_TensorDesc](#nn_tensordesc) \* [OH_NNExecutor_CreateInputTensorDesc](#oh_nnexecutor_createinputtensordesc) (const [OH_NNExecutor](#oh_nnexecutor) \*executor, size_t index) | Creates the description of an input tensor based on the specified index value.|
| [NN_TensorDesc](#nn_tensordesc) \* [OH_NNExecutor_CreateOutputTensorDesc](#oh_nnexecutor_createoutputtensordesc) (const [OH_NNExecutor](#oh_nnexecutor) \*executor, size_t index) | Creates the description of an output tensor based on the specified index value.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNExecutor_GetInputDimRange](#oh_nnexecutor_getinputdimrange) (const [OH_NNExecutor](#oh_nnexecutor) \*executor, size_t index, size_t \*\*minInputDims, size_t \*\*maxInputDims, size_t \*shapeLength) | Obtains the dimension range of all input tensors.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNExecutor_SetOnRunDone](#oh_nnexecutor_setonrundone) ([OH_NNExecutor](#oh_nnexecutor) \*executor, [NN_OnRunDone](#nn_onrundone) onRunDone) | Sets the callback processing function invoked when the asynchronous inference ends.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNExecutor_SetOnServiceDied](#oh_nnexecutor_setonservicedied) ([OH_NNExecutor](#oh_nnexecutor) \*executor, [NN_OnServiceDied](#nn_onservicedied) onServiceDied) | Sets the callback processing function invoked when the device driver service terminates unexpectedly during asynchronous inference.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNExecutor_RunSync](#oh_nnexecutor_runsync) ([OH_NNExecutor](#oh_nnexecutor) \*executor, [NN_Tensor](#nn_tensor) \*inputTensor[], size_t inputCount, [NN_Tensor](#nn_tensor) \*outputTensor[], size_t outputCount) | Performs synchronous inference.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNExecutor_RunAsync](#oh_nnexecutor_runasync) ([OH_NNExecutor](#oh_nnexecutor) \*executor, [NN_Tensor](#nn_tensor) \*inputTensor[], size_t inputCount, [NN_Tensor](#nn_tensor) \*outputTensor[], size_t outputCount, int32_t timeout, void \*userData) | Performs asynchronous inference.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNDevice_GetAllDevicesID](#oh_nndevice_getalldevicesid) (const size_t \*\*allDevicesID, uint32_t \*deviceCount) | Obtains the ID of the device connected to NNRt.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNDevice_GetName](#oh_nndevice_getname) (size_t deviceID, const char \*\*name) | Obtains the name of the specified device.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNDevice_GetType](#oh_nndevice_gettype) (size_t deviceID, [OH_NN_DeviceType](#oh_nn_devicetype) \*deviceType) | Obtains the type of the specified device.|
| [NN_QuantParam](#nn_quantparam) \* [OH_NNQuantParam_Create](#oh_nnquantparam_create) () | Creates an [NN_QuantParam](#nn_quantparam) instance.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNQuantParam_SetScales](#oh_nnquantparam_setscales) ([NN_QuantParam](#nn_quantparam) \*quantParams, const double \*scales, size_t quantCount) | Sets the scaling coefficient for an [NN_QuantParam](#nn_quantparam) instance.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNQuantParam_SetZeroPoints](#oh_nnquantparam_setzeropoints) ([NN_QuantParam](#nn_quantparam) \*quantParams, const int32_t \*zeroPoints, size_t quantCount) | Sets the zero point for an [NN_QuantParam](#nn_quantparam) instance.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNQuantParam_SetNumBits](#oh_nnquantparam_setnumbits) ([NN_QuantParam](#nn_quantparam) \*quantParams, const uint32_t \*numBits, size_t quantCount) | Sets the number of quantization bits for an [NN_QuantParam](#nn_quantparam) instance.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNQuantParam_Destroy](#oh_nnquantparam_destroy) ([NN_QuantParam](#nn_quantparam) \*\*quantParams) | Destroys an [NN_QuantParam](#nn_quantparam) instance.|
| [OH_NNModel](#oh_nnmodel) \* [OH_NNModel_Construct](#oh_nnmodel_construct) (void) | Creates a model instance of the [OH_NNModel](#oh_nnmodel) type and constructs a model instance by using the APIs provided by **OH_NNModel**.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNModel_AddTensorToModel](#oh_nnmodel_addtensortomodel) ([OH_NNModel](#oh_nnmodel) \*model, const [NN_TensorDesc](#nn_tensordesc) \*tensorDesc) | Adds a tensor to a model instance.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNModel_SetTensorData](#oh_nnmodel_settensordata) ([OH_NNModel](#oh_nnmodel) \*model, uint32_t index, const void \*dataBuffer, size_t length) | Sets the tensor value.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNModel_SetTensorQuantParams](#oh_nnmodel_settensorquantparams) ([OH_NNModel](#oh_nnmodel) \*model, uint32_t index, [NN_QuantParam](#nn_quantparam) \*quantParam) | Sets the quantization parameters of a tensor. For details, see [NN_QuantParam](#nn_quantparam).|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNModel_SetTensorType](#oh_nnmodel_settensortype) ([OH_NNModel](#oh_nnmodel) \*model, uint32_t index, [OH_NN_TensorType](#oh_nn_tensortype) tensorType) | Sets the tensor type. For details, see [OH_NN_TensorType](#oh_nn_tensortype).|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNModel_AddOperation](#oh_nnmodel_addoperation) ([OH_NNModel](#oh_nnmodel) \*model, [OH_NN_OperationType](#oh_nn_operationtype) op, const [OH_NN_UInt32Array](_o_h___n_n___u_int32_array.md) \*paramIndices, const [OH_NN_UInt32Array](_o_h___n_n___u_int32_array.md) \*inputIndices, const [OH_NN_UInt32Array](_o_h___n_n___u_int32_array.md) \*outputIndices) | Adds an operator to a model instance.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNModel_SpecifyInputsAndOutputs](#oh_nnmodel_specifyinputsandoutputs) ([OH_NNModel](#oh_nnmodel) \*model, const [OH_NN_UInt32Array](_o_h___n_n___u_int32_array.md) \*inputIndices, const [OH_NN_UInt32Array](_o_h___n_n___u_int32_array.md) \*outputIndices) | Sets an index value for the input and output tensors of a model.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNModel_Finish](#oh_nnmodel_finish) ([OH_NNModel](#oh_nnmodel) \*model) | Completes model composition.|
| void [OH_NNModel_Destroy](#oh_nnmodel_destroy) ([OH_NNModel](#oh_nnmodel) \*\*model) | Destroys a model instance.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNModel_GetAvailableOperations](#oh_nnmodel_getavailableoperations) ([OH_NNModel](#oh_nnmodel) \*model, size_t deviceID, const bool \*\*isSupported, uint32_t \*opCount) | Checks whether all operators in a model are supported by the device. The result is indicated by a Boolean value.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNModel_AddTensor](#oh_nnmodel_addtensor) ([OH_NNModel](#oh_nnmodel) \*model, const [OH_NN_Tensor](_o_h___n_n___tensor.md) \*tensor) | Adds a tensor to a model instance.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNExecutor_SetInput](#oh_nnexecutor_setinput) ([OH_NNExecutor](#oh_nnexecutor) \*executor, uint32_t inputIndex, const [OH_NN_Tensor](_o_h___n_n___tensor.md) \*tensor, const void \*dataBuffer, size_t length) | Sets the data for a single model input.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNExecutor_SetOutput](#oh_nnexecutor_setoutput) ([OH_NNExecutor](#oh_nnexecutor) \*executor, uint32_t outputIndex, void \*dataBuffer, size_t length) | Sets the memory for a single model output.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNExecutor_Run](#oh_nnexecutor_run) ([OH_NNExecutor](#oh_nnexecutor) \*executor) | Executes model inference.|
| [OH_NN_Memory](_o_h___n_n___memory.md) \* [OH_NNExecutor_AllocateInputMemory](#oh_nnexecutor_allocateinputmemory) ([OH_NNExecutor](#oh_nnexecutor) \*executor, uint32_t inputIndex, size_t length) | Applies for shared memory for a single model input on the device.|
| [OH_NN_Memory](_o_h___n_n___memory.md) \* [OH_NNExecutor_AllocateOutputMemory](#oh_nnexecutor_allocateoutputmemory) ([OH_NNExecutor](#oh_nnexecutor) \*executor, uint32_t outputIndex, size_t length) | Applies for shared memory for a single model output on the device.|
| void [OH_NNExecutor_DestroyInputMemory](#oh_nnexecutor_destroyinputmemory) ([OH_NNExecutor](#oh_nnexecutor) \*executor, uint32_t inputIndex, [OH_NN_Memory](_o_h___n_n___memory.md) \*\*memory) | Releases the input memory pointed by the [OH_NN_Memory](_o_h___n_n___memory.md) instance.|
| void [OH_NNExecutor_DestroyOutputMemory](#oh_nnexecutor_destroyoutputmemory) ([OH_NNExecutor](#oh_nnexecutor) \*executor, uint32_t outputIndex, [OH_NN_Memory](_o_h___n_n___memory.md) \*\*memory) | Releases the output memory pointed by the [OH_NN_Memory](_o_h___n_n___memory.md) instance.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNExecutor_SetInputWithMemory](#oh_nnexecutor_setinputwithmemory) ([OH_NNExecutor](#oh_nnexecutor) \*executor, uint32_t inputIndex, const [OH_NN_Tensor](_o_h___n_n___tensor.md) \*tensor, const [OH_NN_Memory](_o_h___n_n___memory.md) \*memory) | Shared memory pointed by the [OH_NN_Memory](_o_h___n_n___memory.md) instance for a single model input.|
| [OH_NN_ReturnCode](#oh_nn_returncode)[OH_NNExecutor_SetOutputWithMemory](#oh_nnexecutor_setoutputwithmemory) ([OH_NNExecutor](#oh_nnexecutor) \*executor, uint32_t outputIndex, const [OH_NN_Memory](_o_h___n_n___memory.md) \*memory) | Shared memory pointed by the [OH_NN_Memory](_o_h___n_n___memory.md) instance for a single model output.|
## Type Description
### NN_OnRunDone
```
typedef void(* NN_OnRunDone) (void *userData, OH_NN_ReturnCode errCode, void *outputTensor[], int32_t outputCount)
```
**Description**
Handle of the callback processing function invoked when the asynchronous inference ends.
Use the **userData** parameter to specify the asynchronous inference to query. The value of **userData** is the same as that passed to [OH_NNExecutor_RunAsync](#oh_nnexecutor_runasync). Use the **errCode** parameter to obtain the return result (defined by [OH_NN_ReturnCode](#oh_nn_returncode) of the asynchronous inference.
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| userData | Identifier of asynchronous inference. The value is the same as the **userData** parameter passed to [OH_NNExecutor_RunAsync](#oh_nnexecutor_runasync).|
| errCode | Return result (defined by [OH_NN_ReturnCode](#oh_nn_returncode) of the asynchronous inference.|
| outputTensor | Output tensor for asynchronous inference. The value is the same as the **outputTensor** parameter passed to [OH_NNExecutor_RunAsync](#oh_nnexecutor_runasync).|
| outputCount | Number of output tensors for asynchronous inference. The value is the same as the **outputCount** parameter passed to [OH_NNExecutor_RunAsync](#oh_nnexecutor_runasync).|
### NN_OnServiceDied
```
typedef void(* NN_OnServiceDied) (void *userData)
```
**Description**
Handle of the callback processing function invoked when the device driver service terminates unexpectedly during asynchronous inference.
You need to rebuild the model if the callback is invoked.
Use the **userData** parameter to specify the asynchronous inference to query. The value of **userData** is the same as that passed to [OH_NNExecutor_RunAsync](#oh_nnexecutor_runasync).
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| userData | Identifier of asynchronous inference. The value is the same as the **userData** parameter passed to [OH_NNExecutor_RunAsync](#oh_nnexecutor_runasync).|
### NN_QuantParam
```
typedef struct NN_QuantParamNN_QuantParam
```
**Description**
Quantization parameter handle.
**Since**: 11
### NN_Tensor
```
typedef struct NN_Tensor NN_Tensor
```
**Description**
Tensor handle.
**Since**: 11
### NN_TensorDesc
```
typedef struct NN_TensorDesc NN_TensorDesc
```
**Description**
Tensor description handle.
**Since**: 11
### OH_NN_DataType
```
typedef enum OH_NN_DataType OH_NN_DataType
```
**Description**
Data types supported by NNRt.
**Since**: 9
### OH_NN_DeviceType
```
typedef enum OH_NN_DeviceType OH_NN_DeviceType
```
**Description**
Device types supported by NNRt.
**Since**: 9
### OH_NN_Format
```
typedef enum OH_NN_Format OH_NN_Format
```
**Description**
Formats of tensor data.
**Since**: 9
### OH_NN_FuseType
```
typedef enum OH_NN_FuseType OH_NN_FuseType
```
**Description**
Activation function types in the fusion operator for NNRt.
**Since**: 9
### OH_NN_Memory
```
typedef struct OH_NN_Memory OH_NN_Memory
```
**Description**
Used to define the memory structure.
**Since**: 9
### OH_NN_OperationType
```
typedef enum OH_NN_OperationType OH_NN_OperationType
```
**Description**
Operator types supported by NNRt.
**Since**: 9
### OH_NN_PerformanceMode
```
typedef enum OH_NN_PerformanceMode OH_NN_PerformanceMode
```
**Description**
Performance modes of the device.
**Since**: 9
### OH_NN_Priority
```
typedef enum OH_NN_Priority OH_NN_Priority
```
**Description**
Priorities of a model inference task.
**Since**: 9
### OH_NN_QuantParam
```
typedef struct OH_NN_QuantParam OH_NN_QuantParam
```
**Description**
Used to define the quantization information.
In quantization scenarios, the 32-bit floating-point data type is quantized into the fixed-point data type according to the following formula:

where, **s** and **z** are quantization parameters, which are stored by **scale** and **zeroPoint** in OH_NN_QuanParam. **r** is a floating point number, **q** is the quantization result, **q_min** is the lower bound of the quantization result, and **q_max** is the upper bound of the quantization result. The calculation method is as follows:
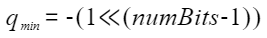

The **clamp** function is defined as follows:

**Since**: 9
### OH_NN_ReturnCode
```
typedef enum OH_NN_ReturnCode OH_NN_ReturnCode
```
**Description**
Error codes for NNRt.
**Since**: 9
### OH_NN_Tensor
```
typedef struct OH_NN_Tensor OH_NN_Tensor
```
**Description**
Used to define the tensor structure.
It is usually used to construct data nodes and operator parameters in a model diagram. When constructing a tensor, you need to specify the data type, number of dimensions, dimension information, and quantization information.
**Since**: 9
### OH_NN_TensorType
```
typedef enum OH_NN_TensorType OH_NN_TensorType
```
**Description**
Defines tensor types.
Tensors are usually used to set the input, output, and operator parameters of a model. When a tensor is used as the input or output of a model (or operator), set the tensor type to **OH_NN_TENSOR**. When the tensor is used as an operator parameter, select an enumerated value other than **OH_NN_TENSOR** as the tensor type. Assume that **pad** of the **OH_NN_OPS_CONV2D** operator is being set. You need to set the **type** attribute of the [OH_NN_Tensor](_o_h___n_n___tensor.md) instance to **OH_NN_CONV2D_PAD**. The settings of other operator parameters are similar. The enumerated values are named in the format OH_NN_{*Operator name*}_{*Attribute name*}.
**Since**: 9
### OH_NN_UInt32Array
```
typedef struct OH_NN_UInt32Array OH_NN_UInt32Array
```
**Description**
Defines the structure for storing 32-bit unsigned integer arrays.
**Since**: 9
### OH_NNCompilation
```
typedef struct OH_NNCompilation OH_NNCompilation
```
**Description**
Compiler handle.
**Since**: 9
### OH_NNExecutor
```
typedef struct OH_NNExecutor OH_NNExecutor
```
**Description**
Executor handle.
**Since**: 9
### OH_NNModel
```
typedef struct OH_NNModel OH_NNModel
```
**Description**
Model handle.
**Since**: 9
## Enum Description
### OH_NN_DataType
```
enum OH_NN_DataType
```
**Description**
Data types supported by NNRt.
**Since**: 9
| Value| Description|
| -------- | -------- |
| OH_NN_UNKNOWN | Unknown type.|
| OH_NN_BOOL | bool type.|
| OH_NN_INT8 | int8 type.|
| OH_NN_INT16 | int16 type.|
| OH_NN_INT32 | int32 type.|
| OH_NN_INT64 | int64 type.|
| OH_NN_UINT8 | uint8 type.|
| OH_NN_UINT16 | uint16 type.|
| OH_NN_UINT32 | uint32 type.|
| OH_NN_UINT64 | uint64 type.|
| OH_NN_FLOAT16 | float16 type.|
| OH_NN_FLOAT32 | float32 type.|
| OH_NN_FLOAT64 | float64 type.|
### OH_NN_DeviceType
```
enum OH_NN_DeviceType
```
**Description**
Device types supported by NNRt.
**Since**: 9
| Value| Description|
| -------- | -------- |
| OH_NN_OTHERS | Devices that are not CPU, GPU, or dedicated accelerator.|
| OH_NN_CPU | CPU.|
| OH_NN_GPU | GPU.|
| OH_NN_ACCELERATOR | Dedicated device accelerator.|
### OH_NN_Format
```
enum OH_NN_Format
```
**Description**
Formats of tensor data.
**Since**: 9
| Value| Description|
| -------- | -------- |
| OH_NN_FORMAT_NONE | The tensor does not have a specific arrangement type (such as scalar or vector).|
| OH_NN_FORMAT_NCHW | The tensor arranges data in NCHW format.|
| OH_NN_FORMAT_NHWC | The tensor arranges data in NHWC format.|
| OH_NN_FORMAT_ND11+ | The tensor arranges data in ND format.|
### OH_NN_FuseType
```
enum OH_NN_FuseType : int8_t
```
**Description**
Activation function types in the fusion operator for NNRt.
**Since**: 9
| Value| Description|
| -------- | -------- |
| OH_NN_FUSED_NONE | The fusion activation function is not specified.|
| OH_NN_FUSED_RELU | Fusion relu activation function.|
| OH_NN_FUSED_RELU6 | Fusion relu6 activation function.|
### OH_NN_OperationType
```
enum OH_NN_OperationType
```
**Description**
Operator types supported by NNRt.
**Since**: 9
| Value| Description|
| -------- | -------- |
| OH_NN_OPS_ADD | Returns the tensor of the sum of the elements corresponding to two input tensors.
Input:
- **input1**: first input tensor, which is of the Boolean or number type.
- **input2**: second input tensor, whose data type must be the same as that of the first tensor.
Parameters:
- **activationType**: integer constant contained in **OH_NN_FuseType**. The specified activation function is called before output.
Output:
**output**: sum of **input1** and **input2**. The data shape is the same as that of the input after broadcasting, and the data type is the same as that of the input with a higher precision.|
| OH_NN_OPS_AVG_POOL | Applies 2D average pooling to the input tensor, which must be in the NHWC format. The int8 quantization input is supported.
If the input contains the **padMode** parameter:
Input:
- **input**: a tensor.
Parameters:
- **kernelSize**: average kernel size. It is an int array with a length of 2 in the format of [kernelHeight, kernelWeight], where the first number indicates the kernel height, and the second number indicates the kernel width.
- **strides**: kernel moving stride. It is an int array with a length of 2 in the format of [strideHeight, strideWeight], where the first number indicates the moving stride in height, and the second number indicates the moving stride in width.
- **padMode**: padding mode, which is optional. It is an **int** value, which can be **0** (same) or **1** (valid). The nearest neighbor value is used for padding. **0** (same): The height and width of the output are the same as those of the input. The total padding quantity is calculated horizontally and vertically and evenly distributed to the top, bottom, left, and right if possible. Otherwise, the last additional padding will be completed from the bottom and right. **1** (valid): The possible maximum height and width of the output will be returned in case of no padding. The excessive pixels will be discarded.
- **roundMode**: boundary processing mode, which is an optional value of the int type. When the pooling core cannot completely cover the input feature map, the output feature map is rounded down. The value **0** indicates rounding down, and the value **1** indicates rounding up.
- **global**: bool value indicating whether to perform the average pooling operation on the entire input tensor.
- **activationType**: integer constant contained in **OH_NN_FuseType**. The specified activation function is called before output.
If the input contains the **padList** parameter:
Input:
- **input**: a tensor.
Parameters:
- **kernelSize**: average kernel size. It is an int array with a length of 2 in the format of [kernelHeight, kernelWeight], where the first number indicates the kernel height, and the second number indicates the kernel width.
- **strides**: kernel moving stride. It is int array with a length of 2 in the format of [strideHeight, strideWeight], where the first number indicates the moving stride in height, and the second number indicates the moving stride in width.
**padList**: padding around **input**. It is an int array with a length of 4 in the format of [top, bottom, left, right], and the nearest neighbor values are used for padding.
- **roundMode**: boundary processing mode, which is an optional value of the int type. When the pooling core cannot completely cover the input feature map, the output feature map is rounded down. The value **0** indicates rounding down, and the value **1** indicates rounding up.
- **global**: bool value indicating whether to perform the average pooling operation on the entire input tensor.
- **activationType**: integer constant contained in **OH_NN_FuseType**. The specified activation function is called before output.
Output:
**output**: average pooling result of the input.|
| OH_NN_OPS_BATCH_NORM | The input tensor is normalized in batches, and a transformation is applied to keep the average output close to 0 and the output standard deviation close to 1.
Input:
- **input**: *n*-dimensional tensor in the shape of [N, ..., C]. The *n*th dimension is the number of channels.
- **scale**: 1D tensor of the scaling factor used to scale the first normalized tensor.
- **offset**: 1D tensor used to move to the first normalized tensor.
- **mean**: 1D tensor of the overall mean value. It is used only for inference. In case of training, this parameter must be left empty.
- **variance**: 1D tensor used for the overall variance. It is used only for inference. In case of training, this parameter must be left empty.
Parameters:
**epsilon**: fixed small additional value.
Output:
**output**: *n*-dimensional output tensor whose shape and data type are the same as those of the input.|
| OH_NN_OPS_BATCH_TO_SPACE_ND | Divides batch dimension of a 4D tensor into small blocks by **blockSize** and interleaves them into the spatial dimension.
Input:
- **input**: input tensor. The dimension will be divided into small blocks, and these blocks will be interleaved into the spatial dimension.
Parameters:
- **blockSize**: size of blocks to be interleaved into the spatial dimension. The value is an array with a length of 2 in the format of [heightBlock, weightBlock].
- **crops**: elements truncated from the spatial dimension of the output. The value is a 2D array with the shape of (2, 2) in the format of [[crop0Start, crop0End], [crop1Start, crop1End]].
Output:
- **output**. If the shape of **input** is (n ,h, w, c), the shape of **output** is (n', h', w', c'), where n' = n / (blockSize[0] \* blockSize[1]), h' = h \* blockSize[0] - crops[0][0] - crops[0][1], w' = w \* blockSize[1] - crops[1][0] - crops[1][1], and c'= c.|
| OH_NN_OPS_BIAS_ADD | Offsets the data in each dimension of the input tensor.
Input:
- **input**: input tensor, which can have two to five dimensions.
- **bias**: offset of the number of input dimensions.
Output:
- **output**: sum of the input tensor and the bias in each dimension.|
| OH_NN_OPS_CAST | Converts the data type in the input tensor.
Input:
- **input**: input tensor.
- **type**: converted data type.
Output:
**output**: converted tensor.|
| OH_NN_OPS_CONCAT | Connects tensors in a specified dimension.
Input:
- **input**: *n* input tensors.
Parameters:
- **axis**: dimension for connecting tensors.
Output:
**output**: result of connecting *n* tensors along the axis.|
| OH_NN_OPS_CONV2D | Sets a 2D convolutional layer.
If the input contains the **padMode** parameter:
Input:
- **input**: input tensor.
- **weight**: convolution weight in the format of [outChannel, kernelHeight, kernelWidth, inChannel/group]. The value of **inChannel** must be exactly divided by the value of **group**.
- **bias**: bias of the convolution. It is an array with a length of [outChannel]. In quantization scenarios, quantization parameters are not required for **bias**. You only need to input data of the **OH_NN_INT32** type. The actual quantization parameters are determined by **input** and **weight**.
Parameters:
- **stride**: moving stride of the convolution kernel in height and weight. It is an int array with a length of 2 in the format of [strideHeight, strideWidth].
- **dilation**: dilation size of the convolution kernel in height and weight. It is an int array with a length of 2 in the format of [dilationHeight, dilationWidth]. The value must be greater than or equal to **1** and cannot exceed the height and width of **input**.
- **padMode**: padding mode of **input**. The value is of the int type and can be **0** (same) or **1** (valid). **0** (same): The height and width of the output are the same as those of the input. The total padding quantity is calculated horizontally and vertically and evenly distributed to the top, bottom, left, and right if possible. Otherwise, the last additional padding will be completed from the bottom and right. **1** (valid): The possible maximum height and width of the output will be returned in case of no padding. The excessive pixels will be discarded.
- **group**: number of groups in which the input is divided by **inChannel**. The value is of the int type. If **group** is **1**, it is a conventional convolution. If **group** is greater than **1** and less than or equal to **inChannel**, it is a group convolution.
- **activationType**: integer constant contained in **OH_NN_FuseType**. The specified activation function is called before output.
If the input contains the **padList** parameter:
Input:
- **input**: input tensor.
- **weight**: convolution weight in the format of [outChannel, kernelHeight, kernelWidth, inChannel/group]. The value of **inChannel** must be exactly divided by the value of **group**.
- **bias**: bias of the convolution. It is an array with a length of [outChannel]. In quantization scenarios, quantization parameters are not required for **bias**. You only need to input data of the **OH_NN_INT32** type. The actual quantization parameters are determined by **input** and **weight**.
Parameters:
- **stride**: moving stride of the convolution kernel in height and weight. It is an int array with a length of 2 in the format of [strideHeight, strideWidth].
- **dilation**: dilation size of the convolution kernel in height and weight. It is an int array with a length of 2 in the format of [dilationHeight, dilationWidth]. The value must be greater than or equal to **1** and cannot exceed the height and width of **input**.
- **padList**: padding around **input**. It is an int array with a length of 4 in the format of [top, bottom, left, right].
- **group**: number of groups in which the input is divided by **inChannel**. The value is of the int type. If **group** is **1**, it is a conventional convolution. If **group** is equal to **inChannel**, it is a 2D depthwise convolution. In this case, group==inChannel==outChannel. If **group** is greater than **1** and less than **inChannel**, it is a group convolution. In this case, outChannel==group.
- **activationType**: integer constant contained in **OH_NN_FuseType**. The specified activation function is called before output.
Output:
- **output**: convolution computing result.|
| OH_NN_OPS_CONV2D_TRANSPOSE | Sets 2D convolution transposition.
If the input contains the **padMode** parameter:
Input:
- **input**: input tensor.
- **weight**: convolution weight in the format of [outChannel, kernelHeight, kernelWidth, inChannel/group]. The value of **inChannel** must be exactly divided by the value of **group**.
- **bias**: bias of the convolution. It is an array with a length of [outChannel]. In quantization scenarios, quantization parameters are not required for **bias**. You only need to input data of the **OH_NN_INT32** type. The actual quantization parameters are determined by **input** and **weight**.
- **stride**: moving stride of the convolution kernel in height and weight. It is an int array with a length of 2 in the format of [strideHeight, strideWidth].
Parameters:
- **dilation**: dilation size of the convolution kernel in height and weight. It is an int array with a length of 2 in the format of [dilationHeight, dilationWidth]. The value must be greater than or equal to **1** and cannot exceed the height and width of **input**.
- **padMode**: padding mode of **input**. The value is of the int type and can be **0** (same) or **1** (valid). **0** (same): The height and width of the output are the same as those of the input. The total padding quantity is calculated horizontally and vertically and evenly distributed to the top, bottom, left, and right if possible. Otherwise, the last additional padding will be completed from the bottom and right. **1** (valid): The possible maximum height and width of the output will be returned in case of no padding. The excessive pixels will be discarded.
- **group**: number of groups in which the input is divided by **inChannel**. The value is of the int type. If **group** is **1**, it is a conventional convolution. If **group** is greater than **1** and less than or equal to **inChannel**, it is a group convolution.
- **outputPads**: padding along the height and width of the output tensor. The value is an int number, a tuple, or a list of two integers. It can be a single integer to specify the same value for all spatial dimensions. The amount of output padding along a dimension must be less than the stride along this dimension.
- **activationType**: integer constant contained in **OH_NN_FuseType**. The specified activation function is called before output.
If the input contains the **padList** parameter:
Input:
- **input**: input tensor.
- **weight**: convolution weight in the format of [outChannel, kernelHeight, kernelWidth, inChannel/group]. The value of **inChannel** must be exactly divided by the value of **group**.
- **bias**: bias of the convolution. It is an array with a length of [outChannel]. In quantization scenarios, quantization parameters are not required for **bias**. You only need to input data of the **OH_NN_INT32** type. The actual quantization parameters are determined by **input** and **weight**.
Parameters:
- **stride**: moving stride of the convolution kernel in height and weight. It is an int array with a length of 2 in the format of [strideHeight, strideWidth].
- **dilation**: dilation size of the convolution kernel in height and weight. It is an int array with a length of 2 in the format of [dilationHeight, dilationWidth]. The value must be greater than or equal to **1** and cannot exceed the height and width of **input**.
- **padList**: padding around **input**. It is an int array with a length of 4 in the format of [top, bottom, left, right].
- **group**: number of groups in which the input is divided by **inChannel**. The value is of the int type. If **group** is **1**, it is a conventional convolution. If **group** is greater than **1** and less than or equal to **inChannel**, it is a group convolution.
- **outputPads**: padding along the height and width of the output tensor. The value is an int number, a tuple, or a list of two integers. It can be a single integer to specify the same value for all spatial dimensions. The amount of output padding along a dimension must be less than the stride along this dimension.
- **activationType**: integer constant contained in **OH_NN_FuseType**. The specified activation function is called before output.
Output:
**output**: computing result after convolution and transposition.|
| OH_NN_OPS_DEPTHWISE_CONV2D_NATIVE | Sets 2D depthwise separable convolution.
If the input contains the **padMode** parameter:
Input:
- **input**: input tensor.
- **weight**: convolution weight in the format of [outChannel, kernelHeight, kernelWidth, 1]. **outChannel** is equal to **channelMultiplier** multiplied by **inChannel**.
- **bias**: bias of the convolution. It is an array with a length of [outChannel]. In quantization scenarios, quantization parameters are not required for **bias**. You only need to input data of the **OH_NN_INT32** type. The actual quantization parameters are determined by **input** and **weight**.
Parameters:
- **stride**: moving stride of the convolution kernel in height and weight. It is an int array with a length of 2 in the format of [strideHeight, strideWidth].
- **dilation**: dilation size of the convolution kernel in height and weight. It is an int array with a length of 2 in the format of [dilationHeight, dilationWidth]. The value must be greater than or equal to **1** and cannot exceed the height and width of **input**.
- **padMode**: padding mode of **input**. The value is of the int type and can be **0** (same) or **1** (valid). **0** (same): The height and width of the output are the same as those of the input. The total padding quantity is calculated horizontally and vertically and evenly distributed to the top, bottom, left, and right if possible. Otherwise, the last additional padding will be completed from the bottom and right. **1** (valid): The possible maximum height and width of the output will be returned in case of no padding. The excessive pixels will be discarded.
- **activationType**: integer constant contained in **OH_NN_FuseType**. The specified activation function is called before output.
If the input contains the **padList** parameter:
Input:
- **input**: input tensor.
- **weight**: convolution weight in the format of [outChannel, kernelHeight, kernelWidth, 1]. **outChannel** is equal to **channelMultiplier** multiplied by **inChannel**.
- **bias**: bias of the convolution. It is an array with a length of [outChannel]. In quantization scenarios, quantization parameters are not required for **bias**. You only need to input data of the **OH_NN_INT32** type. The actual quantization parameters are determined by **input** and **weight**.
Parameters:
- **stride**: moving stride of the convolution kernel in height and weight. It is an int array with a length of 2 in the format of [strideHeight, strideWidth].
- **dilation**: dilation size of the convolution kernel in height and weight. It is an int array with a length of 2 in the format of [dilationHeight, dilationWidth]. The value must be greater than or equal to **1** and cannot exceed the height and width of **input**.
- **padList**: padding around **input**. It is an int array with a length of 4 in the format of [top, bottom, left, right].
- **activationType**: integer constant contained in **OH_NN_FuseType**. The specified activation function is called before output.
Output:
- **output**: convolution computing result.|
| OH_NN_OPS_DIV | Divides two input scalars or tensors.
Input:
- **input1**: first input, which is a number, a bool, or a tensor whose data type is number or Boolean.
- **input2**: second input, which must meet the following requirements: If the first input is a real number or Boolean value, the second input must be a tensor whose data type is real number or Boolean value.
Parameters:
- **activationType**: integer constant contained in **OH_NN_FuseType**. The specified activation function is called before output.
Output:
- **output**: result of dividing **input1** by **input2**.|
| OH_NN_OPS_ELTWISE | Sets parameters to perform product (dot product), sum (addition and subtraction), or max (larger value) on the input.
Input:
- **input1**: first input tensor.
- **input2**: second input tensor.
Parameters:
- **mode**: operation mode. The value is an enumerated value.
Output:
- **output**: computing result, which has the same data type and shape of **output** and **input1**.|
| OH_NN_OPS_EXPAND_DIMS | Adds an additional dimension to a tensor in the given dimension.
Input:
- **input**: input tensor.
- **axis**: index of the dimension to be added. The value is of the int32_t type and must be a constant in the range [-dim-1, dim].
Output:
- **output**: tensor after dimension expansion.|
| OH_NN_OPS_FILL | Creates a tensor of the specified dimensions and fills it with a scalar.
Input:
- **value**: scalar used to fill the tensor.
- **shape**: dimensions of the tensor to be created.
Output:
- **output**: generated tensor, which has the same data type as **value**. The tensor shape is specified by the **shape** parameter.|
| OH_NN_OPS_FULL_CONNECTION | Sets a full connection. The entire input is used as the feature map for feature extraction.
Input:
- **input**: full-connection input tensor.
- **weight**: weight tensor for a full connection.
- **bias**: full-connection bias. In quantization scenarios, quantization parameters are not required for **bias**. You only need to input data of the **OH_NN_INT32** type. The actual quantization parameters are determined by **input** and **weight**.
Parameters:
- **hasBias**: boolean value indicating whether to use the bias offset.
- **activationType**: integer constant contained in **OH_NN_FuseType**. The specified activation function is called before output.
Output:
- **output**: computed tensor.
If the input contains the **axis** or **useAxis** parameter:
Input:
- **input**: full-connection input tensor.
- **weight**: weight tensor for a full connection.
- **bias**: full-connection bias. In quantization scenarios, quantization parameters are not required for **bias**. You only need to input data of the **OH_NN_INT32** type. The actual quantization parameters are determined by **input** and **weight**.
Parameters:
- **axis**: axis in which the full connection is applied. The specified axis and its following axes are converted into a 1D tensor for applying the full connection. The default value is **0**.
- **useAxis**: boolean value indicating whether to use the **axis** parameter. If **axis** is set, **useAxis** is automatically set to **true**. If **useAxis** is set to **true** and **axis** is not specified, the default axis is used to expand full connections. You cannot set **useAxis** to **false** and specify **axis** at the same time. The default value is **false**.
- **hasBias**: boolean value indicating whether to use the bias offset.
- **activationType**: integer constant contained in **OH_NN_FuseType**. The specified activation function is called before output.
Output:
- **output**: computed tensor.|
| OH_NN_OPS_GATHER | Returns the slice of the input tensor based on the specified index and axis.
Input:
- **input**: tensor to be sliced.
- **inputIndices**: indices of the specified input on the axis. The value is an array of the int type and must be in the range [0,input.shape[axis]).
- **axis**: axis on which **input** is sliced. The value is an int32_t array with a length of 1.
Output:
- **output**: sliced tensor.|
| OH_NN_OPS_HSWISH | Calculates the activation value of the input **Hardswish**.
Input:
- An *n*-dimensional input tensor.
Output:
- *n*-dimensional **Hardswish** activation value. The data type is the same as that of **shape** and **input**.|
| OH_NN_OPS_LESS_EQUAL | For **input1** and **input2**, calculate the result of input1[i]<=input2[i] for each pair of elements, where **i** is the index of each element in the input tensor.
Input:
- **input1**: a real number, Boolean value, or tensor whose data type is real number or **OH_NN_BOOL**.
- **input2**: a real number or a Boolean value if **input1** is a tensor, or a tensor whose data type is real number or **OH_NN_BOOL** if **input1** is not a tensor.
Output:
- **output**: a tensor of the **OH_NN_BOOL** type. When a quantization model is used, the quantization parameters of the output cannot be omitted. However, values of the quantization parameters do not affect the result.|
| OH_NN_OPS_MATMUL | Calculates the inner product of **input1** and **input2**.
Input:
- **input1**: *n*-dimensional input tensor.
- **input2**: *n*-dimensional input tensor.
Parameters:
- **TransposeX**: Boolean value indicating whether to transpose **input1**.
- **TransposeY**: Boolean value indicating whether to transpose **input2**.
- **activationType**: integer constant contained in **OH_NN_FuseType**. The specified activation function is called before output.
Output:
- **output**: inner product obtained after calculation. In case of **type!=OH_NN_UNKNOWN**, the output data type is determined by **type**. In case of **type==OH_NN_UNKNOWN**, the output data type depends on the data type converted during computing of **inputX** and **inputY**.|
| OH_NN_OPS_MAXIMUM | Calculates the maximum of **input1** and **input2** element-wise. The inputs of **input1** and **input2** comply with the implicit type conversion rules to make the data types consistent. The input must be two tensors or one tensor and one scalar. If the input contains two tensors, their data types must not be both **OH_NN_BOOL**. Their shapes can be broadcast to the same size. If the input contains one tensor and one scalar, the scalar must be a constant.
Input:
- **input1**: *n*-dimensional input tensor whose data type is real number or **OH_NN_BOOL**.
- **input2**: *n*-dimensional input tensor whose data type is real number or **OH_NN_BOOL**.
Output:
- **output**: *n*-dimensional output tensor. The **shape** and data type of **output** are the same as those of the two inputs with higher precision or bits.|
| OH_NN_OPS_MAX_POOL | Applies 2D maximum pooling to the input tensor.
If the input contains the **padMode** parameter:
Input:
- **input**: a tensor.
Parameters:
- **kernelSize**: maximum kernel size. It is an int array with a length of 2 in the format of [kernelHeight, kernelWeight], where the first number indicates the kernel height, and the second number indicates the kernel width.
- **strides**: kernel moving stride. It is an int array with a length of 2 in the format of [strideHeight, strideWeight], where the first number indicates the moving stride in height, and the second number indicates the moving stride in width.
- **padMode**: padding mode, which is optional. It is an int value, which can be **0** (same) or **1** (valid). The nearest neighbor value is used for padding. **0** (same): The height and width of the output are the same as those of the input. The total padding quantity is calculated horizontally and vertically and evenly distributed to the top, bottom, left, and right if possible. Otherwise, the last additional padding will be completed from the bottom and right. **1** (valid): The possible maximum height and width of the output will be returned in case of no padding. The excessive pixels will be discarded.
- **roundMode**: boundary processing mode, which is an optional value of the int type. When the pooling core cannot completely cover the input feature map, the output feature map is rounded down. The value **0** indicates rounding down, and the value **1** indicates rounding up.
- **global**: bool value indicating whether to perform the average pooling operation on the entire input tensor.
- **activationType**: integer constant contained in **OH_NN_FuseType**. The specified activation function is called before output.
If the input contains the **padList** parameter:
Input:
- **input**: a tensor.
Parameters:
- **kernelSize**: maximum kernel size. It is an int array with a length of 2 in the format of [kernelHeight, kernelWeight], where the first number indicates the kernel height, and the second number indicates the kernel width.
- **strides**: kernel moving stride. It is an int array with a length of 2 in the format of [strideHeight, strideWeight], where the first number indicates the moving stride in height, and the second number indicates the moving stride in width.
**padList**: padding around **input**. It is an int array with a length of 4 in the format of [top, bottom, left, right], and the nearest neighbor values are used for padding.
- **roundMode**: boundary processing mode, which is an optional value of the int type. When the pooling core cannot completely cover the input feature map, the output feature map is rounded down. The value **0** indicates rounding down, and the value **1** indicates rounding up.
- **global**: bool value indicating whether to perform the average pooling operation on the entire input tensor.
- **activationType**: integer constant contained in **OH_NN_FuseType**. The specified activation function is called before output.
Output:
- **output**: tensor obtained after maximum pooling is applied to the input.|
| OH_NN_OPS_MUL | Multiplies elements in the same locations of **input1** and **input2** to obtain the output. If the shapes of **input1** and **input2** are different, **input1** and **input2** can be extended to the same shape through broadcast for multiplication.
Input:
- **input1**: *n*-dimensional tensor.
- **input2**: *n*-dimensional tensor.
Parameters:
- **activationType**: integer constant contained in **OH_NN_FuseType**. The specified activation function is called before output.
Output:
- **output**: product of each element of **input1** and **input2**.|
| OH_NN_OPS_ONE_HOT | Generates a one-hot tensor based on the locations specified by **indices**. The locations specified by **indices** are determined by **onValue**, and other locations are determined by **offValue**.
Input:
- **indices**: *n*-dimensional tensor. Each element in **indices** determines the location of **onValue** in each one-hot vector.
- **depth**, an integer scalar that determines the depth of the one-hot vector. The value of **depth** must be greater than **0**.
- **onValue**: a scalar that specifies a valid value in the one-hot vector.
- **offValue**: a scalar that specifies the values of other locations in the one-hot vector except the valid value.
Parameters:
- **axis**: integer scalar that specifies the dimension for inserting the one-hot. Assume that the shape of **indices** is [N, C], and the value of **depth** is D. When **axis** is **0**, the shape of the output is [D, N, C]. When **axis** is **-1**, the shape of the output is [N, C, D]. When **axis** is **1**, the shape of the output is [N, D, C].
Output:
- **output**: (*n*+1)-dimensional tensor if **indices** is an *n*-dimensional tensor. The output shape is determined by **indices** and **axis**.|
| OH_NN_OPS_PAD | Pads **inputX** in the specified dimensions.
Input:
- **inputX**: *n*-dimensional tensor in [BatchSize, ...] format.
- **paddings**: 2D tensor that specifies the length to pad in each dimension. The shape is [n, 2]. For example, **paddings[i][0]** indicates the number of paddings to be added preceding **inputX** in the *n*th dimension, and **paddings[i][1]** indicates the number of paddings to be added following **inputX** in the *n*th dimension.
Parameters:
- **constantValues**: value to be added to the pad operation. The value is a constant with the same data type as **inputX**.
- **paddingMode**: padding mode. The value is of the **OH_NN_INT32** type. The value **0** indicates that constant 0 is used for padding. The value **1** indicates mirror padding without the symmetry axis. The value **2** indicates mirror padding with the symmetry axis. The value **3** indicates the reserved padding mode.
Output:
- **output**: *n*-dimensional tensor after padding, with the same dimensions and data type as **inputX**. The shape is determined by **inputX** and **paddings**; that is, output.shape[i] = input.shape[i] + paddings[i][0]+paddings[i][1].|
| OH_NN_OPS_POW | Calculates the **y** power of each element in **input**. The input must contain two tensors or one tensor and one scalar. If the input contains two tensors, their data types must not be both **OH_NN_BOOL**, and their shapes must be the same. If the input contains one tensor and one scalar, the scalar must be a constant.
Input:
- **input**: a real number, Boolean value, or tensor whose data type is real number or **OH_NN_BOOL**.
- **y**: a real number, Boolean value, or tensor whose data type is real number or **OH_NN_BOOL**.
Parameters:
- **scale**: an **OH_NN_FLOAT32** scalar indicating the scaling and fusion factor.
- **shift**, an **OH_NN_FLOAT32** scalar indicating the offset of scaling blending.
Output:
- **output**: tensor, whose shape is determined by the shape of **input** and **y** after broadcasting.|
| OH_NN_OPS_SCALE | Scales a tensor.
Input:
- **input**: *n*-dimensional tensor.
- **scale**: scaling tensor.
- **bias**: bias tensor.
Parameters:
- **axis**: dimensions to be scaled.
- **activationType**: integer constant contained in **OH_NN_FuseType**. The specified activation function is called before output.
Output:
- **output**: scaled *n*-dimensional tensor, whose data type is the same as that of **input** and shape is determined by **axis**.|
| OH_NN_OPS_SHAPE | Calculates the shape of the input tensor.
Input:
- **input**: *n*-dimensional tensor.
Output:
- **output**: integer array representing the dimensions of the input tensor.|
| OH_NN_OPS_SIGMOID | Applies the **sigmoid** operation to the input tensor.
Input:
- **input**: *n*-dimensional tensor.
Output:
- **output**: result of the **sigmoid** operation. It is an *n*-dimensional tensor with the same data type and shape as **input**.|
| OH_NN_OPS_SLICE | Slices a tensor of the specified size from the input tensor in each dimension.
Input:
- **input**: *n*-dimensional input tensor.
- **begin**: start of the slice, which is an array of integers greater than or equal to 0.
- **size**: slice length, which is an array of integers greater than or equal to **1**. Assume that a dimension is 1<=size[i]<=input.shape[i]-begin[i].
Parameters:
- **axes**: axis of a slice.
Output:
- **output**: *n*-dimensional tensor obtained by slicing. The **TensorType**, shape, and size of the output are the same as those of the input.|
| OH_NN_OPS_SOFTMAX | Applies the **softmax** operation to the input tensor.
Input:
- **input**: *n*-dimensional input tensor.
Parameters:
- **axis**: dimension in which the **softmax** operation is performed. The value is of the int64 type. It is an integer in the range [-n, n).
Output:
- **output**: result of the **softmax** operation. It is an *n*-dimensional tensor with the same data type and shape as **input**.|
| OH_NN_OPS_SPACE_TO_BATCH_ND | Divides a 4D tensor into small blocks and combines these blocks in the original batch. The number of blocks is **blockShape[0]** multiplied by **blockShape[1]**.
Input:
- **input**: 4D tensor.
Parameters:
- **blockShape**: a pair of integers. Each of them is greater than or equal to **1**.
- **paddings**: a pair of arrays. Each of them consists of two integers. The four integers that form **paddings** must be greater than or equal to **0**. **paddings[0][0]** and **paddings[0][1]** specify the number of paddings in the third dimension, and **paddings[1][0]** and **paddings[1][1]** specify the number of paddings in the fourth dimension.
Output:
- **output**: 4D tensor with the same data type as **input**. The shape is determined by **input**, **blockShape**, and **paddings**. Assume that the input shape is [n, c, h, w], then: output.shape[0] = n \* blockShape[0] \* blockShape[1] output.shape[1] = c output.shape[2] = (h + paddings[0][0] + paddings[0][1]) / blockShape[0] output.shape[3] = (w + paddings[1][0] + paddings[1][1]) / blockShape[1]. Note that (h + paddings[0][0] + paddings[0][1]) and (w + paddings[1][0] + paddings[1][1]) must be exactly divisible by blockShape[0] and blockShape[1].|
| OH_NN_OPS_SPLIT | Splits the input into multiple tensors along the axis dimension. The number of tensors is specified by **outputNum**.
Input:
- **input**: *n*-dimensional tensor.
Parameters:
- **outputNum**: number of output tensors. The data type is int.
- **sizeSplits**: size of each tensor split from the input. The value is a 1D tensor of the **int** type. If **sizeSplits** is empty, the input will be evenly split into tensors of the same size. In this case, **input.shape[axis]** can be exactly divisible by **outputNum**. If **sizeSplits** is not empty, the sum of all its elements must be equal to **input.shape[axis]**.
- **axis**: splitting dimension of the int type.
Output:
- **outputs**: array of *n*-dimensional tensors, with the same data type and dimensions. The data type of each tensor is the same as that of **input**.|
| OH_NN_OPS_SQRT | Calculates the square root of a tensor.
Input:
- **input**: *n*-dimensional tensor.
Output:
- **output**: square root of the input. It is an *n*-dimensional tensor with the same data type and shape as **input**.|
| OH_NN_OPS_SQUARED_DIFFERENCE | Calculates the square of the difference between two tensors. The **SquaredDifference** operator supports tensor and tensor subtraction. If two tensors have different **TensorTypes**, the operator converts the low-precision tensor to a high-precision one. If two tensors have different shapes, the two tensors can be extended to tensors with the same shape through broadcast.
Input:
- input1: subtractor, which is a tensor of the OH_NN_FLOAT16, OH_NN_FLOAT32, OH_NN_INT32, or OH_NN_BOOL type.
- input2: subtractor, which is a tensor of the OH_NN_FLOAT16, OH_NN_FLOAT32, OH_NN_INT32, or OH_NN_BOOL type.
Output:
- **output**: square of the difference between two inputs. The output shape is determined by **input1** and **input2**. If they have the same shape, the output tensor has the same shape as them. If they have different shapes, perform the broadcast operation on **input1** and **input2** and perform subtraction. **TensorType** of the output is the same as that of the input tensor with higher precision.|
| OH_NN_OPS_SQUEEZE | Removes the dimension with a length of 1 from the specified axis. The int8 quantization input is supported. Assume that the input shape is [2, 1, 1, 2, 2] and axis is [0,1], the output shape is [2, 1, 2, 2], which means the dimension with a length of 0 between dimension 0 and dimension 1 is removed.
Input:
- **input**: *n*-dimensional tensor.
Parameters:
- **axis**: dimension to be removed. The value is of int64_t type and can be an integer in the range [-n, n) or an array.
Output:
- **output**: output tensor.|
| OH_NN_OPS_STACK | Stacks multiple tensors along the specified axis. If each tensor has *n* dimensions before stacking, the output tensor will have *n*+1 dimensions.
Input:
- **input**: input for stacking, which can contain multiple *n*-dimensional tensors. Each of them must have the same shape and type.
Parameters:
- **axis**: dimension for tensor stacking, which is an integer. The value range is [-(n+1),(n+1)), which means a negative number is allowed.
Output:
- **output**: stacking result of the input along the axis dimension. The value is an *n*+1-dimensional tensor and has the same **TensorType** as the input.|
| OH_NN_OPS_STRIDED_SLICE | Slices a tensor with the specified stride.
Input:
- **input**: *n*-dimensional input tensor.
- **begin**: start of slicing, which is a 1D tensor. The length of **begin** is *n*. **begin[i]** specifies the start of slicing in the *i*th dimension.
- **end**: end of slicing, which is a 1D tensor. The length of **end** is *n*. **end[i]** specifies the end of slicing in the *i*th dimension.
- **strides**: slicing stride, which is a 1D tensor. The length of **strides** is *n*. strides[i] specifies the stride at which the tensor is sliced in the *i*th dimension.
Parameters:
- **beginMask**: an integer used to mask **begin**. **beginMask** is represented in binary code. In case of binary(beginMask)[i]==1, for the *i*th dimension, elements are sliced from the first element at **strides[i]** until the end[i]-1 element.
- **endMask**: an integer used to mask **end**. **endMask** is represented in binary code. In case of binary(endMask)[i]==1, elements are sliced from the element at the **begin[i]** location in the *i*th dimension until the tensor boundary at **strides[i]**.
- **ellipsisMask**: integer used to mask **begin** and **end**. **ellipsisMask** is represented in binary code. In case of binary(ellipsisMask)[i]==1, elements are sliced from the first element at **strides[i]** in the *i*th dimension until the tensor boundary. Only one bit of **binary(ellipsisMask)** can be a non-zero value.
- **newAxisMask**: new dimension, which is an integer. **newAxisMask** is represented in binary code. In case of binary(newAxisMask)[i]==1, a new dimension with a length of 1 is inserted into the *i*th dimension.
- **shrinkAxisMask**: shrinking dimension, which is an integer. **shrinkAxisMask** is represented in binary code. In the case of binary(shrinkAxisMask)[i]==1, all elements in the *i*th dimension will be discarded, and the length of the *i*th dimension is shrunk to **1**.
Output:
- A tensor, with the same data type as **input**. The number of dimensions of the output tensor is rank(input[0])+1.|
| OH_NN_OPS_SUB | Calculates the difference between two tensors.
Input:
- **input1**: minuend, which is a tensor.
- **input2**: subtrahend, which is a tensor.
Parameters:
- **activationType**: integer constant contained in **OH_NN_FuseType**. The specified activation function is called before output.
Output:
- **output**: difference between the two tensors. The shape of the output is determined by input1 and input2. When the shapes of input1 and input2 are the same, the shape of the output is the same as that of input1 and input2. If the shapes of input1 and input2 are different, the output is obtained after the broadcast operation is performed on input1 or input2. **TensorType** of the output is the same as that of the input tensor with higher precision.|
| OH_NN_OPS_TANH | Computes hyperbolic tangent of the input tensor.
Input:
- **input**: *n*-dimensional tensor.
Output:
- **output**: hyperbolic tangent of the input. The **TensorType** and tensor shape are the same as those of the input.|
| OH_NN_OPS_TILE | Copies a tensor for the specified number of times.
Input:
- **input**: *n*-dimensional tensor.
- **multiples**: number of times that the input tensor is copied in each dimension. The value is a 1D tensor. The length *m* is not less than the number of dimensions, that is, *n*.
Parameters:
- **dims**: 1D tensor, which specifies the index of the dimension to be copied.
Output:
- **output**, *m*-dimensional tensor. **TensorType** is the same as **input**. If **input** and **multiples** have the same length, **input** and **output** have the same number of dimensions. If the length of **multiples** is greater than *n*, 1 is used to fill the input dimension, and then the input is copied in each dimension the specified times to obtain the *m*-dimensional tensor.|
| OH_NN_OPS_TRANSPOSE | Transposes data of **input** based on **permutation**.
Input:
- **input**: *n*-dimensional tensor to be transposed.
- **permutation**: 1D tensor whose length is the same as the number of dimensions of **input**.
Output:
- **output**: *n*-dimensional tensor. **TensorType** of **output** is the same as that of **input**, and the output shape is determined by the shape and **permutation** of **input**.|
| OH_NN_OPS_REDUCE_MEAN | Calculates the average value in the specified dimension. If **keepDims** is set to **false**, the number of dimensions is reduced for the input; if **keepDims** is set to **true**, the number of dimensions is retained.
Input:
- **input**: *n*-dimensional input tensor, where *n* is less than 8.
- **axis**: dimension used to calculate the average value. The value is a 1D tensor. The value range of each element in **axis** is [–n, n).
Parameters:
- **keepDims**: whether to retain the dimension. The value is a Boolean value.
- **reduceToEnd**: a boolean value indicating whether to perform the reduce operation until the last axis.
- **coeff**: an OH_NN_FLOAT32 scalar indicating the output scaling factor.
Output:
- **output**: *m*-dimensional output tensor whose data type is the same as that of the input. If **keepDims** is **false**, m < n. If **keepDims** is **true**, m==n.|
| OH_NN_OPS_RESIZE_BILINEAR | The Bilinear method is used to deform the input based on the given parameters.
Input:
- **input**: 4D input tensor. Each element in the input cannot be less than 0. The input layout must be [batchSize, height, width, channels].
Parameters:
- **newHeight**: resized height of the 4D tensor.
- **newWidth**: resized width of the 4D tensor.
- **preserveAspectRatio**: whether to maintain the height/width ratio of **input** after resizing.
- **coordinateTransformMode**: an int32 integer indicating the coordinate transformation method used by the Resize operation. The value 0 indicates **ASYMMETRIC**. The value **1** indicates **ALIGN_CORNERS**. The value **2** indicates **HALF_PIXEL**.
- **excludeOutside**: an int64 floating point number. When its value is **1**, the sampling weight of the part that exceeds the boundary of **input** is set to **0**, and other weights are normalized.
Output:
- **output**: *n*-dimensional tensor, with the same shape and data type as **input**. |
| OH_NN_OPS_RSQRT | Calculates the reciprocal of the square root of an input tensor.
Input:
- **input**: *n*-dimensional tensor, where *n* is less than 8. Each element of the tensor cannot be less than **0**.
Output:
- **output**: *n*-dimensional tensor, with the same shape and data type as **input**. |
| OH_NN_OPS_RESHAPE | Reshapes an input tensor.
Input:
- **input**: *n*-dimensional input tensor.
- **inputShape**: shape of the output tensor. The value is a 1D constant tensor.
Output:
- **output**: tensor whose data type is the same as that of **input** and shape is determined by **InputShape**.|
| OH_NN_OPS_PRELU | Calculates the PReLU activation value of **input** and **weight**.
Input:
- **input**: *n*-dimensional tensor. If *n* is greater than or equal to **2**, **inputX** must be [BatchSize, ..., Channels]. The second dimension is the number of channels.
- **weight**: 1D tensor. The length of **weight** must be **1** or equal to the number of channels. If the length of **weight** is **1**, all channels of **input** share the same weight. If the length of **weight** is equal to the number of channels, each channel exclusively has a weight. If *n* is less than **2** for **input**, the **weight** length must be **1**.
Output:
- **output**: PReLU activation value of **input**, with the same shape and data type as **input**.|
| OH_NN_OPS_RELU | Calculates the Relu activation value of **input**.
Input:
- **input**: *n*-dimensional input tensor.
Output:
- **output**: *n*-dimensional Relu tensor, with the same data type and shape as the input tensor.|
| OH_NN_OPS_RELU6 | Calculates the Relu6 activation value of the input, that is, calculate min(max(x, 0), 6) for each element x in the input.
Input:
- **input**: *n*-dimensional input tensor.
Output:
- **output**: *n*-dimensional Relu6 tensor, with the same data type and shape as the input tensor.|
| OH_NN_OPS_LAYER_NORM | Applies layer normalization for a tensor from the specified axis.
Input:
- **input**: *n*-dimensional input tensor.
- **gamma**: *m*-dimensional tensor. The dimensions of **gamma** must be the same as the shape of the part of the input tensor to normalize.
- **beta**: *m*-dimensional tensor with the same shape as **gamma**.
Parameters:
- **beginAxis**: an **OH_NN_INT32** scalar that specifies the axis from which normalization starts. The value range is [1, rank(input)).
- **epsilon**: an **OH_NN_FLOAT32** scalar that represents a tiny amount in the normalization formula. The common value is **1e-5**.
- **beginParamsAxis**: the start axis of the input (gamma, beta) to be normalized.
Output:
- **output**: *n*-dimensional tensor, with the same data type and shape as the input tensor.|
| OH_NN_OPS_REDUCE_PROD | Calculates the accumulated value for a tensor along the specified dimension.
Input:
- **input**: *n*-dimensional input tensor, where *n* is less than 8.
- **axis**: dimension used to calculate the product. The value is a 1D tensor. The value range of each element in **axis** is [–n, n).
Parameters:
- **keepDims**: whether to retain the dimension. The value is a Boolean value. If its value is **true**, the number of output dimensions is the same as that of the input. If its value is **false**, the number of output dimensions is reduced.
- **reduceToEnd**: a boolean value indicating whether to perform the reduce operation until the last axis.
- **coeff**: an **OH_NN_FLOAT32** scalar indicating the output scaling factor.
Output:
- **output**: *m*-dimensional output tensor whose data type is the same as that of the input. If **keepDims** is **false**, m < n. If **keepDims** is **true**, m==n.|
| OH_NN_OPS_REDUCE_ALL | Calculates the logical AND of the specified dimension. If **keepDims** is **false**, the number of input dimensions is reduced. If **keepDims** is **true**, the number of input dimensions is retained.
Input:
- An *n*-dimensional input tensor, where *n* is less than 8.
- A 1D tensor specifying the dimension used to operate the logical OR. The value range of each element in **axis** is [–n, n).
Parameters:
- **keepDims**: whether to retain the dimension. The value is a Boolean value.
- **reduceToEnd**: a boolean value indicating whether to perform the reduce operation until the last axis.
- **coeff**: an **OH_NN_FLOAT32** scalar indicating the output scaling factor.
Output:
- **output**: *m*-dimensional output tensor whose data type is the same as that of the input. If **keepDims** is **false**, m < n. If **keepDims** is **true**, m==n.|
| OH_NN_OPS_QUANT_DTYPE_CAST | Converts the data type.
Input:
- **input**: *n*-dimensional tensor. For conversion between the quantization type and floating-point type, the input tensor must contain quantization parameters.
Parameters:
- **srcT**: data type of the input.
- **dstT**: data type of the output.
- **axis**: the dimension for extracting quantization parameters. If the size of the input tensor quantization parameter is **1**, the operator function is used for layer quantization conversion and this parameter does not take effect. If the size of the input tensor quantization parameter is greater than **1**, the operator function is used for channel quantization conversion and this parameter takes effect.
Output:
- **output**: *n*-dimensional tensor. The data type is determined by **dstT**. The output shape is the same as the input shape.|
| OH_NN_OPS_TOP_K | Obtains the values and indices of the largest *k* entries in the last dimension.
Input:
- **input**: *n*-dimensional tensor.
- **k**: first *k* records of data and their indices.
Parameters:
- **sorted**: order of sorting. The value **true** means descending and **false** means ascending.
- **axis**: an **OH_NN_INT32** scalar that specifies the dimension to be sorted. The default value is **-1**, pointing to the last dimension.
Output:
- **output0**: largest *k* elements in each slice of the last dimension.
- **output1**: index of the value in the last dimension of the input.|
| OH_NN_OPS_ARG_MAX | Returns the index of the maximum tensor value across axes.
Input:
- **input**: *n*-dimensional tensor (N, *), where * means any number of additional dimensions.
Parameters:
- **axis**: dimension for calculating the index of the maximum.
- **keepDims**: a boolean value indicatin gwhether to maintain the input tensor dimension.
- **topK**: number of maximum values to be returned. The default value is **1**. If **topK** is equal to **1**, the index of the max value in the input tensor is returned. If **topK** is greater than **1**, the indices of the first top K max values in the input tensor is returned. If multiple values in the input tensor are the max value, any of them is returned.
- **outMaxValue**: whether to output the maximum value. The default value is **false**.
Output:
- **output**: index of the maximum input tensor on the axis. The value is a tensor.|
| OH_NN_OPS_UNSQUEEZE | Adds a dimension based on the value of **axis**.
Input:
- **input**: *n*-dimensional tensor.
Parameters:
- **axis**: dimension to add. The value of **axis** can be an integer or an array of integers. The value range of the integer is [-n, n).
Output:
- **output**: output tensor.|
| OH_NN_OPS_GELU | Activates the Gaussian error linear unit. The int quantization input is not supported. output=0.5*input*(1+tanh(input/2))
Input:
- An *n*-dimensional input tensor.
Parameters:
- **approximate**: a boolean value that represents the option of the approximation function. If the value is **true**, the approximation function is a Tanh function. If the value is **false**, the approximation function is an Erf function.
Output:
- **output**: *n*-dimensional Relu tensor, with the same data type and shape as the input tensor.|
| OH_NN_OPS_UNSTACK12+ | Factorizes the input tensor based on the axis.
Input:
- **input**: *n*-dimensional tensor.
Parameters:
- **axis**: an **OH_NN_INT32** scalar that specifies the axis for matrix factorization. The value range is [-n, n).
Output:
- **output**: a collection of multiple tensors factorized from the input. Each tensor has the same shape.|
| OH_NN_OPS_ABS12+ | Calculates the absolute value of the input data.
Input:
- **input**: *n*-dimensional tensor.
Output:
- **output**: *n*-dimensional tensor whose shape and data type are the same as those of the input.|
| OH_NN_OPS_ERF12+ | Gaussian error function, which calculates the error of the input data by element.
Input:
- input: *n*-dimensional tensor. The number of dimensions must be less than **8**. The data type can only be **OH_NN_FLOAT32** or **OH_NN_FLOAT16**.
Output:
- **output**: *n*-dimensional tensor. The data type and shape are the same as those of the input.|
| OH_NN_OPS_EXP12+ | Calculates the input exponent by element. The calculation formula is output = base ^ (shift + scale \* input), in which the base number is **base>0**. The default value is **-1**, indicating that the base number is a natural constant **e**.
Input:
- **input**: *n*-dimensional tensor.
Parameters:
- **base**: base of the exponential function. The default value is **-1**, indicating that the base is a natural constant **e**.
- **scale**: scaling factor of the exponent. The default value is **1**.
- **shift**: offset of the exponent. The default value is **0**.
Output:
- **output**: *n*-dimensional tensor, which is output result of the exponential function.|
| OH_NN_OPS_LESS12+ | Calculates the result of input1[i]<input2[i] by element for **input1** and **input2**, where **i** is the index of each element in the input tensor.
Input:
- **input1**, which can be a real number, Boolean value, or tensor whose data type is real number or OH_NN_BOOL.
- **input2**: a real number or a Boolean value if **input1** is a tensor, or a tensor whose data type is real number or **OH_NN_BOOL** if **input1** is not a tensor.
Output:
- **output**: a tensor of the **OH_NN_BOOL** type. When a quantization model is used, the quantization parameters of the output cannot be omitted. However, values of the quantization parameters do not affect the result.|
| OH_NN_OPS_SELECT12+ | Determines whether the output is selected from input 1 or input 2 by element based on the input conditions. If the condition is **true**, the output is selected from input 1. If the condition is **false**, the output is selected from input 2. When the condition is a tensor, the shapes of the three inputs must be the same.
Input:
- **condition**: decision condition, which can be a real number or an n-dimensional tensor.
- **input1**: input 1 to be selected.
- **input2**: input 2 to be selected.
Output:
- **output**: *n*-dimensional tensor whose shape and data type are the same as those of the input.|
| OH_NN_OPS_SQUARE12+ | Calculates the square of the input by element.
Input:
- **input**: *n*-dimensional tensor.
Output:
- **output**: *n*-dimensional tensor whose shape and data type are the same as those of the input.|
| OH_NN_OPS_FLATTEN12+ | Specifies the axis to flatten the input tensor.
Input:
- **input**: *n*-dimensional tensor.
Parameters:
- **axis**: axis along which the input is flattened. For a tensor whose input dimension is (d_0, d_1, ..., d_n), the output dimension should be (d_0\*\d_1\*...\*d_(axis-1), d_axis\*d_(axis+1)\*...\*d_n).
Output:
- **output**: 2D tensor after being flattened.|
| OH_NN_OPS_DEPTH_TO_SPACE12+ | Rearranges the depth data blocks of the input tensor into spatial dimensions.
Input:
- **input**: 4-dimensional tensor in NHWC or NCHW format. Currently, only NHWC is supported. The shape is [batchSize, height, width, channels].
Parameters:
- **blockSize**: size of the block to be converted. The value must be an integer.
- **mode**: conversion mode. The value **0** indicates DCR, and the value **1** indicates CRD. DCR indicates depth-column-row sequential rearrangement, and CRD indicates column-row-depth sequential rearrangement.
Output:
- **output**: 4-dimensional tensor. The format is the same as that of the input tensor, and the shape is [batchSize, height \* blockSize, weight \* blockSize, channel / blockSize^2].|
| OH_NN_OPS_RANGE12+ | Generates a sequence tensor. The generation range is [start, limit), and the step is delta.
Input:
- **input**: n-dimensional tensor. The output data type is the same as that of the input.
Parameters:
- **start**: start number of a generated sequence.
- **limit**: end number of the generated sequence, excluding this value.
- **delta**: step. Partial data is skipped from the generated sequence range by step.
Output:
- **output**: 1-dimensional sequence tensor.|
| OH_NN_OPS_INSTANCE_NORM12+ | Performs standardization processing on each input channel, so that the average value of each input channel is 0 and the variance is 1.
Input:
- **input**: 4-dimensional tensor.
- **scale**: 1D tensor. The scaling coefficient and size are the same as the number of input channels.
- **bias**: 1D tensor that represents the bias constant. The size is the same as the number of input channels.
Parameters:
- **epsilon**: a small value added to the denominator to ensure calculation stability.
Output:
- **output**: 4-dimensional tensor with the same shape as the input.|
| OH_NN_OPS_CONSTANT_OF_SHAPE12+ | Generates a tensor with the specified shape.
Input:
- **input**: 1D tensor that represents the shape of the target tensor.
Parameters:
- **dataType**: data type of the target tensor.
- **value**: value of the target tensor, which is a single-element array whose data type is **OH_NN_FLOAT32**.
Output:
- **output**: target tensor.|
| OH_NN_OPS_BROADCAST_TO12+ | Broadcasts a tensor to an adapted shape.
Input:
- **input**: *n*-dimensional tensor.
Parameters:
- **shape**: 1D tensor that represents the expected output shape.
Output:
- **output**: broadcast tensor.|
| OH_NN_OPS_EQUAL12+ | Calculates the result of input1[i] = input2[i] by element for **input1** and **input2**, where **i** is the index of each element in the input tensor.
Input:
- **input1**, which can be a real number, Boolean value, or tensor whose data type is real number or OH_NN_BOOL.
- **input2**: a real number or a Boolean value if **input1** is a tensor, or a tensor whose data type is real number or **OH_NN_BOOL** if **input1** is not a tensor.
Output:
- **output**: a tensor of the **OH_NN_BOOL** type. When a quantization model is used, the quantization parameters of the output cannot be omitted. However, values of the quantization parameters do not affect the result.|
| OH_NN_OPS_GREATER12+ | Calculates the result of input1[i]>input2[i] by element for **input1** and **input2**, where **i** is the index of each element in the input tensor.
Input:
- **input1**, which can be a real number, Boolean value, or tensor whose data type is real number or OH_NN_BOOL.
- **input2**: a real number or a Boolean value if **input1** is a tensor, or a tensor whose data type is real number or **OH_NN_BOOL** if **input1** is not a tensor.
Output:
- **output**: a tensor of the **OH_NN_BOOL** type. When a quantization model is used, the quantization parameters of the output cannot be omitted. However, values of the quantization parameters do not affect the result.|
| OH_NN_OPS_NOT_EQUAL12+ | Calculates the result of input1[i] != input2[i] by element for **input1** and **input2**, where **i** is the index of each element in the input tensor.
Input:
- **input1**, which can be a real number, Boolean value, or tensor whose data type is real number or OH_NN_BOOL.
- **input2**: a real number or a Boolean value if **input1** is a tensor, or a tensor whose data type is real number or **OH_NN_BOOL** if **input1** is not a tensor.
Output:
- **output**: a tensor of the **OH_NN_BOOL** type. When a quantization model is used, the quantization parameters of the output cannot be omitted. However, values of the quantization parameters do not affect the result.|
| OH_NN_OPS_GREATER_EQUAL12+ | Calculates the result of input1[i]>=input2[i] by element for **input1** and **input2**, where **i** is the index of each element in the input tensor.
Input:
- **input1**, which can be a real number, Boolean value, or tensor whose data type is real number or OH_NN_BOOL.
- **input2**: a real number or a Boolean value if **input1** is a tensor, or a tensor whose data type is real number or **OH_NN_BOOL** if **input1** is not a tensor.
Output:
- **output**: a tensor of the **OH_NN_BOOL** type. When a quantization model is used, the quantization parameters of the output cannot be omitted. However, values of the quantization parameters do not affect the result.|
| OH_NN_OPS_LEAKY_RELU12+ | Calculates the activation value of the input **leakyRelu**.
Input:
- **input**: *n*-dimensional tensor.
Parameters:
- **negativeSlope**: slope when the input is less than **0**, which controls the output size. The data type is **OH_NN_FLOAT32**.
Output:
- **output**: *n*-dimensional tensor whose shape and data type are the same as those of the input.|
| OH_NN_OPS_LSTM12+ | Performs long-term and short-term memory (LSTM) network calculations on the input.
Input:
- **input**: 3D tensor in the shape of [seqLen, batchSize, inputSize].
- **wIh**: weight from the input to the hidden layer. The shape is [numDirections\*numLayers, 4\*hiddenSize, inputSize].
- **wHh**: weight from the hidden layer to the hidden layer. The shape is [numDirections\*numLayers, 4\*hiddenSize, inputSize].
- **bias**: bias from the input and hidden layers to the hidden layer. The shape is [numDirections\*numLayers, 8\*hiddenSize].
- **hx**: initial hidden status of the unit gate. The shape is [numDirections\*numLayers, batchSize, hiddenSize].
- **cx**: initial cell status of the unit gate. The shape is [numDirections\*numLayers, batchSize, hiddenSize].
Parameters:
- **bidirectional**: boolean value indicating whether the LSTM is bidirectional.
- **hasBias**: boolean value indicating whether the unit gate has a bias.
- **inputSize**: input size.
- **hiddenSize**: status size of the hidden layer.
- **numLayers**: number of LSTM network layers.
- **numDirections**: number of directions of the LSTM network.
- **dropout**: drop probability. The probability that the input of each layer except the first layer is discarded is [0.0, 1.0].
- **zoneoutCell**: probability that the control unit retains the previous state. The default value is **0**.
- **zoneoutHidden**: probability that the hidden layer retains the previous state. The default value is **0**.
- **projSize**: projection size. If the value is greater than **0**, the LSTM projection is used. The default value is **0**.
Output:
- **output**: 3D tensor in the shape of [seqLen, batchSize, numDirections\*realHiddenSize]. The channels of all output tensors are stitched for output.
- **hy**: output tensor of the last hidden layer. The shape is [numDirections\*numLayers, batchSize, realHiddenSize].
- **cy**: output tensor of the unit gate at the last layer. The shape is [numDirections\*numLayers, batchSize, HiddenSize].|
| OH_NN_OPS_CLIP12+ | Crops the value of the input tensor to a value between the specified minimum and maximum values.
Input:
- **input**: *n*-dimensional tensor or tensor list or tuple. Tensors of any dimensions are supported.
Parameters:
- **min**: minimum cropping value.
- **max**: maximum cropping value.
Output:
- **output**: tensor after value cropping. The shape and data type are the same as those of the input.|
| OH_NN_OPS_ALL12+ | Checks whether all elements of the specified dimension in the input are non-zero values. If all elements are non-zero values, **true** is returned for the corresponding dimension. Otherwise, **false** is returned for the corresponding dimension.
Input:
- **input**: *n*-dimensional tensor in the shape of (N, \*), where \* indicates any number of additional dimensions.
- **axis**: 1D tensor that represents the dimension to be calculated.
Parameters:
- **keepDims**: whether to retain the dimension of the output tensor.
Output:
- **output**: 1-dimensional or *n*-dimensional tensor whose data type is **OH_NN_BOOL**. It is the tensor output after non-zero judgment.|
| OH_NN_OPS_ASSERT12+ | Asserts whether the given condition is true. If the result of the given condition is false, the tensor list in **data** is printed, where **summarize** is used to determine the number of tensor entries to be printed.
Input:
- **condition**: condition to evaluate.
- **data**: tensor to be printed when the condition is false.
Parameters:
- **summarize**: number of entries in each tensor to be printed.
Output:
- **output**: output result. If the condition is not true, **Error** is returned.|
| OH_NN_OPS_COS12+ | Calculates the cosine value of the input data by element.
Input:
- **input**: *n*-dimensional tensor whose data type is **OH_NN_FLOAT64**, **OH_NN_FLOAT32**, or **OH_NN_FLOAT16**.
Output:
- **output**: *n*-dimensional tensor whose shape and data type are the same as those of the input.|
| OH_NN_OPS_LOG12+ | Calculates the natural logarithm of the input by element.
Input:
- **input**: *n*-dimensional tensor whose data type is **OH_NN_FLOAT64**, **OH_NN_FLOAT32**, or **OH_NN_FLOAT16**. The value must be greater than **0**.
Output:
- **output**: *n*-dimensional tensor whose shape and data type are the same as those of the input.|
| OH_NN_OPS_LOGICAL_AND12+ | Calculates the logical AND operation of two input tensors by element.
Input:
- **input1**: *n*-dimensional tensor whose data type is **OH_NN_BOOL**.
- **input2**: *n*-dimensional tensor whose data type is **OH_NN_BOOL** and the shape is the same as that of **input1**.
Output:
- **output**: *n*-dimensional tensor whose data type is **OH_NN_BOOL**. It is the result of the logical AND operation.|
| OH_NN_OPS_LOGICAL_NOT12+ | Calculates the logical NOT operation of two input tensors by element.
Input:
- **input**: *n*-dimensional tensor whose data type is **OH_NN_BOOL**.
Output:
- **output**: *n*-dimensional tensor whose data type is **OH_NN_BOOL**. It is the result of the logical NOT operation.|
| OH_NN_OPS_MOD12+ | Performs the mod operation on the input tensor. **input1** and **input2** must be converted into the same data type based on the data type conversion rules. The input must contain two tensors or contain one tensor and one scalar. If the input contains two tensors, their data types must not be both **OH_NN_BOOL** and they can be broadcast to the same shape. If the input contains one tensor and one scalar, the scalar input can only be a constant.
Input:
- **input1**: scalar or tensor for the mod operation. The data type is numeric, **OH_NN_BOOL**, or *n*-dimensional numeric tensor.
- **input2**: cofactor for the mod operation. When the first input is an *n*-dimensional tensor, the second input can be a numeric or **OH_NN_BOOL** value, or an *n*-dimensional numeric tensor. If the first input is a numeric or **OH_NN_BOOL** value, the second input must be an *n*-dimensional numeric tensor.
Output:
- **output**: *n*-dimensional tensor. The shape is the same as that of the broadcast input. The data type is the data type with higher precision in the two inputs.|
| OH_NN_OPS_NEG12+ | Calculates the opposite number of the input by element.
Input:
- **input**: *n*-dimensional tensor whose data type is numeric.
Output:
- **output**: *n*-dimensional tensor whose shape and data type are the same as those of the input.|
| OH_NN_OPS_RECIPROCAL12+ | Calculates the reciprocal of the input exponent by element.
Input:
- **input**: *n*-dimensional tensor whose data type is **OH_NN_FLOAT64**, **OH_NN_FLOAT32**, or **OH_NN_FLOAT16**.
Output:
- **output**: *n*-dimensional tensor whose shape and data type are the same as those of the input.|
| OH_NN_OPS_SIN12+ | Calculates the sine value of the input by element.
Input:
- **input**: *n*-dimensional tensor whose data type is **OH_NN_FLOAT64**, **OH_NN_FLOAT32**, or **OH_NN_FLOAT16**.
Output:
- **output**: *n*-dimensional tensor whose shape and data type are the same as those of the input.|
| OH_NN_OPS_WHERE12+ | Selects proper elements from **input1** and **input2** based on the specified condition.
Input:
- **condition**: *n*-dimensional tensor whose data type is **OH_NN_BOOL**. If the element is **true**, the element corresponding to **input1** is selected. If the element is **false**, the element corresponding to **input2** is selected.
- **input1**: *n*-dimensional tensor to be selected.
- **input2**: *n*-dimensional tensor to be selected.
Output:
- **output**: output result.|
| OH_NN_OPS_SPARSE_TO_DENSE12+ | Converts a sparse tensor to a dense tensor.
Input:
- **indices**: 2D tensor indicating the location of an element in the sparse tensor.
- **values**: 1D tensor indicating the value mapping to the location in **indices**.
- **sparseShape**: shape of a tensor, which consists of two positive integers. The shape is (N, C).
Output:
- **output**: tensor after conversion whose data type is the same as that of **value** and the shape is specified by **sparseShape**.|
| OH_NN_OPS_LOGICAL_OR12+ | Calculates the logical OR operation of two input tensors by element.
Input:
- **input1**: *n*-dimensional tensor whose data type is **OH_NN_BOOL**.
- **input2**: *n*-dimensional tensor whose data type is **OH_NN_BOOL** and the shape is the same as that of **input1**.
Output:
- **output**: *n*-dimensional tensor whose data type is **OH_NN_BOOL**. It is the result of the logical OR operation.|
| OH_NN_OPS_CEIL12+ | Rounds up each input element.
Input:
- **input**: *n*-dimensional tensor whose data type is **OH_NN_FLOAT64**, **OH_NN_FLOAT32**, or **OH_NN_FLOAT16**.
Output:
- **output**: *n*-dimensional tensor whose shape and data type are the same as those of the input.|
| OH_NN_OPS_CROP12+ | Crops the input tensor with the specified shape based on the specified axis and offset.
Input:
- **input**: *n*-dimensional tensor to be cropped.
- **shape**: 1D tensor indicating the size of the tensor to be cropped.
Parameters:
- **axis**: start axis of the cropped area. The value range is [0,1, ...,r-1], where **r** is the rank of the input tensor, and a negative number indicates the reverse value.
- **offset**: start offset of the cropped area.
Output:
- **output**: cropped tensor.|
| OH_NN_OPS_DETECTION_POST_PROCESS12+ | Performs post-processing on the output of the object detection model. Specific operations include decoding the bounding box, category probability, and score output by the model, performing Non-Max suppression (NMS) to remove the overlapping bounding box, and outputting the detection result.
Input:
- **bbox**: bounding box.
- **scores**: category score probability.
- **anchors**: anchors used to generate coordinates and size of the candidate box of a detection box. In an object detection task, candidate boxes are a series of rectangular boxes preset in an image according to specific rules. These rectangular boxes usually have different sizes and aspect ratios, and are used to preliminarily predict and screen a target in the image.
Parameters:
- **inputSize**: size of the input tensor.
- **scale**: scaling factor used to convert the output image from the normalized form to the coordinates of the original image.
- **nmsIoUThreshold**: Non-Max suppression threshold, which is used to remove duplicate detection boxes.
- **nmsScoreThreshold**: confidence threshold, which is used to filter low-confidence detection boxes.
- **maxDetections**: maximum number of detection boxes that can be output for each image.
- **detectionsPerClass**: maximum number of detections for each category.
- **maxClassesPerDetection**: maximum number of detection categories in each detection box.
- **numClasses**: total number of detection categories.
- **useRegularNms**: boolean value indicating whether to use the IoU threshold-based Non-Max suppression algorithm. When the value is **true**, the IoU threshold-based Non-Max suppression algorithm is used to filter overlapped target boxes and retain the target box with the highest score. If this parameter is set to **false**, the IoU threshold-based Non-Max suppression algorithm is not applicable. The target boxes are sorted based on the score and the target box with the highest score is retained.
- **outQuantized**: boolean value indicating whether the output needs to be quantized.
Output:
- **bboxes**: 3D tensor whose internal array indicates the coordinates of the object detection box.
- **classes**: 2D tensor whose internal value indicates the class index corresponding to each detection box.
- **confidences**: 2D tensor. The internal value indicates the confidence of the detected object.
- **numDetections**: number of detection results.|
| OH_NN_OPS_FLOOR12+ | Rounds down each input element.
Input:
- **input**: *n*-dimensional tensor whose data type is **OH_NN_FLOAT64**, **OH_NN_FLOAT32**, or **OH_NN_FLOAT16**.
Output:
- **output**: *n*-dimensional tensor whose shape and data type are the same as those of the input.|
| OH_NN_OPS_L2_NORMALIZE12+ | Performs L2 regularization on the input tensor based on the specified axis.
Input:
- **input**: *n*-dimensional tensor for L2 regularization.
Parameters:
- **axis**: specified dimension for regularization. The value **-1** indicates the last dimension.
- **epsilon**: a small value added to the denominator to ensure calculation stability. The default value is **1e-6**.
- **activationType**: activation function type.
Output:
- **output**: output tensor whose data type and shape are the same as those of the input.|
| OH_NN_OPS_LOG_SOFTMAX12+ | Performs exponential operations on each element of the input tensor and normalizes the operation result to obtain a probability distribution vector.
Input:
- **input**: 2D tensor whose shape is [batchSize, numClasses] and data type is **OH_NN_FLOAT64**, **OH_NN_FLOAT32**, or **OH_NN_FLOAT16**.
Parameters:
- **axis**: dimension for calculation.
Output:
- **output**: 2D tensor that represents the probability vector after calculation.|
| OH_NN_OPS_LRN12+ | Normalizes the local response of the input.
Input:
- **input**: 4D tensor to be normalized.
Parameters:
- **depthRadius**: scalar type indicating the half width of the normalized window.
- **bias**: bias used to avoid division by zero. The default value is **1**.
- **alpha**: ratio coefficient. The default value is **1**.
- **beta**: exponential variable. The default value is **0.5**.
- **normRegion**: normalized region. The default value is **0**, indicating that the normalized region is **ACROSS_CHANNELS**. Currently, only this mode is supported.
Output:
- **output**: normalized output tensor whose shape and data type are the same as those of the input.|
| OH_NN_OPS_MINIMUM12+ | Calculates the minimum value of two tensors by element. The input must conain two tensors or contain one tensor and one scalar. If the input contains two tensors, their data types must not be both boolean and they can be broadcast to the same shape. If the input contains one tensor and one scalar, the scalar input can only be a constant.
Input:
- **input1**: *n*-dimensional tensor whose data type can be numeric or boolean.
- **input2**: *n*-dimensional tensor whose data type can be numeric or boolean.
Output:
- **output**: comparison result tensor whose shape and data type are the same as those of the input.|
| OH_NN_OPS_RANK12+ | Calculates the rank of a tensor.
Input:
- **input**: *n*-dimensional tensor.
Output:
- **output**: 0D tensor indicating the input rank. The data type is int32.|
| OH_NN_OPS_REDUCE_MAX12+ | Calculates the maximum value of the input tensors in the specified dimension. If **keepDims** is **false**, the dimension of the output tensor is reduced. If **keepDims** is **true**, the dimension of the output tensor and the input tensor remain unchanged.
Input:
- **input**: *n*-dimensional tensor, where n<8.
- **axis**: dimension used to calculate the maximum value.
Parameters:
- **keepDims**: whether to retain the dimension. The value is a Boolean value.
- **reduceToEnd**: a boolean value indicating whether to perform the reduce operation until the last axis.
- **coeff**: an OH_NN_FLOAT32 scalar indicating the output scaling factor.
Output:
- **output**: *m*-dimensional output tensor whose data type is the same as that of the input. If **keepDims** is **false**, m < n. If **keepDims** is **true**, m==n.|
| OH_NN_OPS_REDUCE_MIN12+ | Calculates the minimum value of the input tensors in the specified dimension. If **keepDims** is **false**, the dimension of the output tensor is reduced. If **keepDims** is **true**, the dimension of the output tensor and the input tensor remain unchanged.
Input:
- **input**: *n*-dimensional tensor, where n<8.
- **axis**: dimension used to calculate the minimum value.
Parameters:
- **keepDims**: whether to retain the dimension. The value is a Boolean value.
- **reduceToEnd**: a boolean value indicating whether to perform the reduce operation until the last axis.
- **coeff**: an OH_NN_FLOAT32 scalar indicating the output scaling factor.
Output:
- **output**: *m*-dimensional output tensor whose data type is the same as that of the input. If **keepDims** is **false**, m < n. If **keepDims** is **true**, m==n.|
| OH_NN_OPS_REDUCE_SUM12+ | Calculates the sum of the input tensors in the specified dimension. If **keepDims** is **false**, the dimension of the output tensor is reduced. If **keepDims** is **true**, the dimension of the output tensor and the input tensor remain unchanged.
Input:
- **input**: *n*-dimensional tensor, where n<8.
- **axis**: dimension used to calculate the sum.
Parameters:
- **keepDims**: whether to retain the dimension. The value is a Boolean value.
- **reduceToEnd**: a boolean value indicating whether to perform the reduce operation until the last axis.
- **coeff**: an OH_NN_FLOAT32 scalar indicating the output scaling factor.
Output:
- **output**: *m*-dimensional output tensor whose data type is the same as that of the input. If **keepDims** is **false**, m < n. If **keepDims** is **true**, m==n.|
| OH_NN_OPS_ROUND12+ | Rounds off the input tensor to approximate the value.
Input:
- **input**: *n*-dimensional tensor.
Output:
- **output**: *n*-dimensional tensor whose shape and data type are the same as those of the input.|
| OH_NN_OPS_SCATTER_ND12+ | Distributes the updated value to a new tensor based on the specified index.
Input:
- **indices**: indices scattered in the new tensor. The data type is **OH_NN_INT64** or **OH_NN_INT32**. The index rank is at least 2, and the value of the last dimension of **indices** is less than the size of the input shape.
- **updates**: tensor to be updated.
- **shape**: shape of the output tensor. The data type is the same as that of **indices**.
Output:
- **output**: updated tensor. The data type is the same as that of **updates**, and the shape is the same as that of **shape**.|
| OH_NN_OPS_SPACE_TO_DEPTH12+ | Rearranges spatial dimension data blocks of the input tensor into depth dimensions.
Input:
- **input**: 4-dimensional tensor in NHWC or NCHW format. Currently, only NHWC is supported. The shape is [batchSize, height, width, channels].
Parameters:
- **blockSize**: size of the block to be converted. The value must be an integer.
Output:
- **output**: 4-dimensional tensor. The format is the same as that of the input tensor, and the shape is [batchSize, height / blockSize, weight / blockSize, channel \* blockSize^2].|
| OH_NN_OPS_SWISH12+ | Calculates Swish activation for the input tensor by element.
Input:
- **input**: *n*-dimensional tensor.
Output:
- *n*-dimensional tensor. The data type and shape are the same as those of the input.|
| OH_NN_OPS_REDUCE_L212+ | Calculates the L2 norm of the input tensors in the specified dimension. If **keepDims** is **false**, the dimension of the output tensor is reduced. If **keepDims** is **true**, the dimension of the output tensor and the input tensor remain unchanged.
Input:
- **input**: *n*-dimensional tensor, where n<8.
- **axis**: axis used to calculate the dimension of the L2 norm.
Parameters:
- **keepDims**: whether to retain the dimension. The value is a Boolean value.
- **reduceToEnd**: a boolean value indicating whether to perform the reduce operation until the last axis.
- **coeff**: an OH_NN_FLOAT32 scalar indicating the output scaling factor.
Output:
- **output**: *m*-dimensional output tensor whose data type is the same as that of the input. If **keepDims** is **false**, m < n. If **keepDims** is **true**, m==n.|
| OH_NN_OPS_HARD_SIGMOID12+ | Calculates HardSigmoid activation for the input tensor by element.
Input:
- **input**: *n*-dimensional tensor.
Output:
- *n*-dimensional tensor. The data type and shape are the same as those of the input.|
| OH_NN_OPS_GATHER_ND12+ | Obtains the element at the specified location of the input tensor based on the specified index.
Input:
- **input**: *n*-dimensional tensor.
- **indices**: *m*-dimensional tensor whose data type is **OH_NN_INT64** or **OH_NN_INT32**.
Output:
- *n*-dimensional tensor. The data type is the same as that of the input. The shape is the concatenation of the first dimension (m-1) of **indices** and the last dimension (size of the last dimension of n-indices) of input.|
### OH_NN_PerformanceMode
```
enum OH_NN_PerformanceMode
```
**Description**
Performance modes of the device.
**Since**: 9
| Value| Description|
| -------- | -------- |
| OH_NN_PERFORMANCE_NONE | No performance mode preference.|
| OH_NN_PERFORMANCE_LOW | Low power consumption mode.|
| OH_NN_PERFORMANCE_MEDIUM | Medium performance mode.|
| OH_NN_PERFORMANCE_HIGH | High performance mode.|
| OH_NN_PERFORMANCE_EXTREME | Ultimate performance mode.|
### OH_NN_Priority
```
enum OH_NN_Priority
```
**Description**
Priorities of a model inference task.
**Since**: 9
| Value| Description|
| -------- | -------- |
| OH_NN_PRIORITY_NONE | No priority preference.|
| OH_NN_PRIORITY_LOW | Low priority.|
| OH_NN_PRIORITY_MEDIUM | Medium priority.|
| OH_NN_PRIORITY_HIGH | High priority.|
### OH_NN_ReturnCode
```
enum OH_NN_ReturnCode
```
**Description**
Error codes for NNRt.
**Since**: 9
| Value| Description|
| -------- | -------- |
| OH_NN_SUCCESS | The operation is successful.|
| OH_NN_FAILED | Operation failed.|
| OH_NN_INVALID_PARAMETER | Invalid parameter.|
| OH_NN_MEMORY_ERROR | Memory-related error, for example, insufficient memory, memory data copy failure, or memory application failure.|
| OH_NN_OPERATION_FORBIDDEN | Invalid operation.|
| OH_NN_NULL_PTR | Null pointer.|
| OH_NN_INVALID_FILE | Invalid file.|
| OH_NN_UNAVALIDABLE_DEVICE | Hardware error, for example, HDL service crash.
**Deprecated**: This API is deprecated since API version 11.
**Substitute**: OH_NN_UNAVAILABLE_DEVICE is recommended.|
| OH_NN_INVALID_PATH | Invalid path.|
| OH_NN_TIMEOUT11+ | Execution timed out.|
| OH_NN_UNSUPPORTED11+ | Not supported.|
| OH_NN_CONNECTION_EXCEPTION11+ | Connection error.|
| OH_NN_SAVE_CACHE_EXCEPTION11+ | Failed to save the cache.|
| OH_NN_DYNAMIC_SHAPE11+ | Dynamic shape.|
| OH_NN_UNAVAILABLE_DEVICE11+ | Hardware error, for example, HDL service crash.|
### OH_NN_TensorType
```
enum OH_NN_TensorType
```
**Description**
Defines tensor types.
Tensors are usually used to set the input, output, and operator parameters of a model. When a tensor is used as the input or output of a model (or operator), set the tensor type to **OH_NN_TENSOR**. When the tensor is used as an operator parameter, select an enumerated value other than **OH_NN_TENSOR** as the tensor type. Assume that **pad** of the **OH_NN_OPS_CONV2D** operator is being set. You need to set the **type** attribute of the [OH_NN_Tensor](_o_h___n_n___tensor.md) instance to **OH_NN_CONV2D_PAD**. The settings of other operator parameters are similar. The enumerated values are named in the format OH_NN_{*Operator name*}_{*Attribute name*}.
**Since**: 9
| Value| Description|
| -------- | -------- |
| OH_NN_TENSOR | Used when the tensor is used as the input or output of a model (or operator).|
| OH_NN_ADD_ACTIVATIONTYPE | Used when the tensor is used as the **activationType** parameter of the Add operator.|
| OH_NN_AVG_POOL_KERNEL_SIZE | Used when the tensor is used as the **kernelSize** parameter of the AvgPool operator.|
| OH_NN_AVG_POOL_STRIDE | Used when the tensor is used as the **stride** parameter of the AvgPool operator.|
| OH_NN_AVG_POOL_PAD_MODE | Used when the tensor is used as the **AvgPool** parameter of the AvgPool operator. |
| OH_NN_AVG_POOL_PAD | Used when the tensor is used as the **pad** parameter of the AvgPool operator.|
| OH_NN_AVG_POOL_ACTIVATION_TYPE | Used when the tensor is used as the **activationType** parameter of the AvgPool operator. |
| OH_NN_BATCH_NORM_EPSILON | Used when the tensor is used as the **eosilon** parameter of the BatchNorm operator.|
| OH_NN_BATCH_TO_SPACE_ND_BLOCKSIZE | Used when the tensor is used as the **blockSize** parameter of the BatchToSpaceND operator.|
| OH_NN_BATCH_TO_SPACE_ND_CROPS | Used when the tensor is used as the **crops** parameter of the BatchToSpaceND operator.|
| OH_NN_CONCAT_AXIS | Used when the tensor is used as the **axis** parameter of the Concat operator.|
| OH_NN_CONV2D_STRIDES | Used when the tensor is used as the **strides** parameter of the Conv2D operator.|
| OH_NN_CONV2D_PAD | Used when the tensor is used as the **pad** parameter of the Conv2D operator.|
| OH_NN_CONV2D_DILATION | Used when the tensor is used as the **dilation** parameter of the Conv2D operator.|
| OH_NN_CONV2D_PAD_MODE | Used when the tensor is used as the **padMode** parameter of the Conv2D operator.|
| OH_NN_CONV2D_ACTIVATION_TYPE | Used when the tensor is used as the **activationType** parameter of the Conv2D operator.|
| OH_NN_CONV2D_GROUP | Used when the tensor is used as the **group** parameter of the Conv2D operator. |
| OH_NN_CONV2D_TRANSPOSE_STRIDES | Used when the tensor is used as the **strides** parameter of the Conv2DTranspose operator.|
| OH_NN_CONV2D_TRANSPOSE_PAD | Used when the tensor is used as the **pad** parameter of the Conv2DTranspose operator.|
| OH_NN_CONV2D_TRANSPOSE_DILATION | Used when the tensor is used as the **dilation** parameter of the Conv2DTranspose operator. |
| OH_NN_CONV2D_TRANSPOSE_OUTPUT_PADDINGS | Used when the tensor is used as the **outputPaddings** parameter of the Conv2DTranspose operator. |
| OH_NN_CONV2D_TRANSPOSE_PAD_MODE | Used when the tensor is used as the **padMode** parameter of the Conv2DTranspose operator. |
| OH_NN_CONV2D_TRANSPOSE_ACTIVATION_TYPE | Used when the tensor is used as the **activationType** parameter of the Conv2DTranspose operator. |
| OH_NN_CONV2D_TRANSPOSE_GROUP | Used when the tensor is used as the **group** parameter of the Conv2DTranspose operator. |
| OH_NN_DEPTHWISE_CONV2D_NATIVE_STRIDES | Used when the tensor is used as the **strides** parameter of the DepthwiseConv2dNative operator. |
| OH_NN_DEPTHWISE_CONV2D_NATIVE_PAD | Used when the tensor is used as the **pad** parameter of the DepthwiseConv2dNative operator. |
| OH_NN_DEPTHWISE_CONV2D_NATIVE_DILATION | Used when the tensor is used as the **dilation** parameter of the DepthwiseConv2dNative operator. |
| OH_NN_DEPTHWISE_CONV2D_NATIVE_PAD_MODE | Used when the tensor is used as the **padMode** parameter of the DepthwiseConv2dNative operator. |
| OH_NN_DEPTHWISE_CONV2D_NATIVE_ACTIVATION_TYPE | Used when the tensor is used as the **activationType** parameter of the DepthwiseConv2dNative operator. |
| OH_NN_DIV_ACTIVATIONTYPE | Used when the tensor is used as the **activationType** parameter of the Div operator. |
| OH_NN_ELTWISE_MODE | Used when the tensor is used as the **mode** parameter of the Eltwise operator. |
| OH_NN_FULL_CONNECTION_AXIS | Used when the tensor is used as the **axis** parameter of the FullConnection operator. |
| OH_NN_FULL_CONNECTION_ACTIVATIONTYPE | Used when the tensor is used as the **activationType** parameter of the FullConnection operator. |
| OH_NN_MATMUL_TRANSPOSE_A | Used when the tensor is used as the **transposeA** parameter of the Matmul operator. |
| OH_NN_MATMUL_TRANSPOSE_B | Used when the tensor is used as the **transposeB** parameter of the Matmul operator. |
| OH_NN_MATMUL_ACTIVATION_TYPE | Used when the tensor is used as the **activationType** parameter of the Matmul operator. |
| OH_NN_MAX_POOL_KERNEL_SIZE | Used when the tensor is used as the **kernelSize** parameter of the MaxPool operator. |
| OH_NN_MAX_POOL_STRIDE | Used when the tensor is used as the **stride** parameter of the MaxPool operator. |
| OH_NN_MAX_POOL_PAD_MODE | Used when the tensor is used as the **padMode** parameter of the MaxPool operator. |
| OH_NN_MAX_POOL_PAD | Used when the tensor is used as the **pad** parameter of the MaxPool operator. |
| OH_NN_MAX_POOL_ACTIVATION_TYPE | Used when the tensor is used as the **activationType** parameter of the MaxPool operator. |
| OH_NN_MUL_ACTIVATION_TYPE | Used when the tensor is used as the **activationType** parameter of the Mul operator. |
| OH_NN_ONE_HOT_AXIS | Used when the tensor is used as the **axis** parameter of the OneHot operator. |
| OH_NN_PAD_CONSTANT_VALUE | Used when the tensor is used as the **constantValue** parameter of the Pad operator. |
| OH_NN_SCALE_ACTIVATIONTYPE | Used when the tensor is used as the **activationType** parameter of the Scale operator. |
| OH_NN_SCALE_AXIS | Used when the tensor is used as the **axis** parameter of the Scale operator. |
| OH_NN_SOFTMAX_AXIS | Used when the tensor is used as the **axis** parameter of the Softmax operator. |
| OH_NN_SPACE_TO_BATCH_ND_BLOCK_SHAPE | Used when the tensor is used as the **BlockShape** parameter of the SpaceToBatchND operator. |
| OH_NN_SPACE_TO_BATCH_ND_PADDINGS | Used when the tensor is used as the **Paddings** parameter of the SpaceToBatchND operator. |
| OH_NN_SPLIT_AXIS | Used when the tensor is used as the **Axis** parameter of the Split operator. |
| OH_NN_SPLIT_OUTPUT_NUM | Used when the tensor is used as the **OutputNum** parameter of the Split operator. |
| OH_NN_SPLIT_SIZE_SPLITS | Used when the tensor is used as the **SizeSplits** parameter of the Split operator. |
| OH_NN_SQUEEZE_AXIS | Used when the tensor is used as the **Axis** parameter of the Squeeze operator. |
| OH_NN_STACK_AXIS | Used when the tensor is used as the **Axis** parameter of the Stack operator. |
| OH_NN_STRIDED_SLICE_BEGIN_MASK | Used when the tensor is used as the **BeginMask** parameter of the StridedSlice operator. |
| OH_NN_STRIDED_SLICE_END_MASK | Used when the tensor is used as the **EndMask** parameter of the StridedSlice operator. |
| OH_NN_STRIDED_SLICE_ELLIPSIS_MASK | Used when the tensor is used as the **EllipsisMask** parameter of the StridedSlice operator. |
| OH_NN_STRIDED_SLICE_NEW_AXIS_MASK | Used when the tensor is used as the **NewAxisMask** parameter of the StridedSlice operator. |
| OH_NN_STRIDED_SLICE_SHRINK_AXIS_MASK | Used when the tensor is used as the **ShrinkAxisMask** parameter of the StridedSlice operator. |
| OH_NN_SUB_ACTIVATIONTYPE | Used when the tensor is used as the **ActivationType** parameter of the Sub operator. |
| OH_NN_REDUCE_MEAN_KEEP_DIMS | Used when the tensor is used as the **keepDims** parameter of the ReduceMean operator. |
| OH_NN_RESIZE_BILINEAR_NEW_HEIGHT | Used when the tensor is used as the **newHeight** parameter of the ResizeBilinear operator. |
| OH_NN_RESIZE_BILINEAR_NEW_WIDTH | Used when the tensor is used as the **newWidth** parameter of the ResizeBilinear operator. |
| OH_NN_RESIZE_BILINEAR_PRESERVE_ASPECT_RATIO | Used when the tensor is used as the **preserveAspectRatio** parameter of the ResizeBilinear operator. |
| OH_NN_RESIZE_BILINEAR_COORDINATE_TRANSFORM_MODE | Used when the tensor is used as the **coordinateTransformMode** parameter of the ResizeBilinear operator. |
| OH_NN_RESIZE_BILINEAR_EXCLUDE_OUTSIDE | Used when the tensor is used as the **excludeOutside** parameter of the ResizeBilinear operator. |
| OH_NN_LAYER_NORM_BEGIN_NORM_AXIS | Used when the tensor is used as the **beginNormAxis** parameter of the LayerNorm operator. |
| OH_NN_LAYER_NORM_EPSILON | Used when the tensor is used as the **epsilon** parameter of the LayerNorm operator. |
| OH_NN_LAYER_NORM_BEGIN_PARAM_AXIS | Used when the tensor is used as the **beginParamsAxis** parameter of the LayerNorm operator. |
| OH_NN_LAYER_NORM_ELEMENTWISE_AFFINE | Used when the tensor is used as the **elementwiseAffine** parameter of the LayerNorm operator. |
| OH_NN_REDUCE_PROD_KEEP_DIMS | Used when the tensor is used as the **keepDims** parameter of the ReduceProd operator. |
| OH_NN_REDUCE_ALL_KEEP_DIMS | Used when the tensor is used as the **keepDims** parameter of the ArgMax operator. |
| OH_NN_QUANT_DTYPE_CAST_SRC_T | Used when the tensor is used as the **srcT** parameter of the QuantDTypeCast operator. |
| OH_NN_QUANT_DTYPE_CAST_DST_T | Used when the tensor is used as the **dstT** parameter of the QuantDTypeCast operator. |
| OH_NN_TOP_K_SORTED | Used when the tensor is used as the **Sorted** parameter of the Topk operator. |
| OH_NN_ARG_MAX_AXIS | Used when the tensor is used as the **axis** parameter of the ArgMax operator. |
| OH_NN_ARG_MAX_KEEPDIMS | Used when the tensor is used as the **keepDims** parameter of the ArgMax operator. |
| OH_NN_UNSQUEEZE_AXIS | Used when the tensor is used as the **Axis** parameter of the Unsqueeze operator. |
| OH_NN_UNSTACK_AXIS12+ | Used when the tensor is used as the **axis** parameter of the Unstack operator. |
| OH_NN_FLATTEN_AXIS12+ | Used when the tensor is used as the **axis** parameter of the Flatten operator. |
| OH_NN_DEPTH_TO_SPACE_BLOCK_SIZE12+ | Used when the tensor is used as the **blockSize** parameter of the DepthToSpace operator.|
| OH_NN_DEPTH_TO_SPACE_MODE12+ | Used when the tensor is used as the **mode** parameter of the DepthToSpace operator. |
| OH_NN_RANGE_START12+ | Used when the tensor is used as the **start** parameter of the Range operator. |
| OH_NN_RANGE_LIMIT12+ | Used when the tensor is used as the **limit** parameter of the Range operator. |
| OH_NN_RANGE_DELTA12+ | Used when the tensor is used as the **delta** parameter of the Range operator. |
| OH_NN_CONSTANT_OF_SHAPE_DATA_TYPE12+ | Used when the tensor is used as the **dataType** parameter of the ConstantOfShape operator. |
| OH_NN_CONSTANT_OF_SHAPE_VALUE12+ | Used when the tensor is used as the **value** parameter of the ConstantOfShape operator. |
| OH_NN_BROADCAST_TO_SHAPE12+ | Used when the tensor is used as the **shape** parameter of the BroadcastTo operator. |
| OH_NN_INSTANCE_NORM_EPSILON12+ | Used when the tensor is used as the **epsilon** parameter of the InstanceNorm operator. |
| OH_NN_EXP_BASE12+ | Used when the tensor is used as the **base** parameter of the Exp operator. |
| OH_NN_EXP_SCALE12+ | Used when the tensor is used as the **scale** parameter of the Exp operator. |
| OH_NN_EXP_SHIFT12+ | Used when the tensor is used as the **shift** parameter of the Exp operator. |
| OH_NN_LEAKY_RELU_NEGATIVE_SLOPE12+ | Used when the tensor is used as the **negativeSlope** parameter of the LeakyRelu operator. |
| OH_NN_LSTM_BIDIRECTIONAL12+ | Used when the tensor is used as the **bidirectional** parameter of the LSTM operator. |
| OH_NN_LSTM_HAS_BIAS12+ | Used when the tensor is used as the **hasBias** parameter of the LSTM operator. |
| OH_NN_LSTM_INPUT_SIZE12+ | Used when the tensor is used as the **inputSize** parameter of the LSTM operator. |
| OH_NN_LSTM_HIDDEN_SIZE12+ | Used when the tensor is used as the **hiddenSize** parameter of the LSTM operator. |
| OH_NN_LSTM_NUM_LAYERS12+ | Used when the tensor is used as the **numLayers** parameter of the LSTM operator. |
| OH_NN_LSTM_NUM_DIRECTIONS12+ | Used when the tensor is used as the **numDirections** parameter of the LSTM operator. |
| OH_NN_LSTM_DROPOUT12+ | Used when the tensor is used as the **numDirections** parameter of the LSTM operator. |
| OH_NN_LSTM_ZONEOUT_CELL12+ | Used when the tensor is used as the **zoneoutCell** parameter of the LSTM operator. |
| OH_NN_LSTM_ZONEOUT_HIDDEN12+ | Used when the tensor is used as the **zoneoutHidden** parameter of the LSTM operator. |
| OH_NN_LSTM_PROJ_SIZE12+ | Used when the tensor is used as the **projSize** parameter of the LSTM operator. |
| OH_NN_CLIP_MAX12+ | Used when the tensor is used as the **max** parameter of the LSTM operator. |
| OH_NN_CLIP_MIN12+ | Used when the tensor is used as the **min** parameter of the LSTM operator. |
| OH_NN_ALL_KEEP_DIMS12+ | Used when the tensor is used as the **keepDims** parameter of the All operator. |
| OH_NN_ASSERT_SUMMARIZE12+ | Used when the tensor is used as the **summarize** parameter of the All operator. |
| OH_NN_POW_SCALE12+ | Used when the tensor is used as the **scale** parameter of the Pow operator. |
| OH_NN_POW_SHIFT12+ | Used when the tensor is used as the **shift** parameter of the Pow operator. |
| OH_NN_AVG_POOL_ROUND_MODE12+ | Used when the tensor is used as the **RoundMode** parameter of the AvgPool operator. |
| OH_NN_AVG_POOL_GLOBAL12+ | Used when the tensor is used as the **global** parameter of the AvgPool operator. |
| OH_NN_FULL_CONNECTION_HAS_BIAS12+ | Used when the tensor is used as the **hasBias** parameter of the FullConnection operator. |
| OH_NN_FULL_CONNECTION_USE_AXIS12+ | Used when the tensor is used as the **useAxis** parameter of the FullConnection operator. |
| OH_NN_GELU_APPROXIMATE12+ | Used when the tensor is used as the **approximate** parameter of the GeLU operator. |
| OH_NN_MAX_POOL_ROUND_MODE12+ | Used when the tensor is used as the **RoundMode** parameter of the MaxPool operator. |
| OH_NN_MAX_POOL_GLOBAL12+ | Used when the tensor is used as the **global** parameter of the MaxPool operator. |
| OH_NN_PAD_PADDING_MODE12+ | Used when the tensor is used as the **paddingMode** parameter of the Pad operator. |
| OH_NN_REDUCE_MEAN_REDUCE_TO_END12+ | Used when the tensor is used as the **reduceToEnd** parameter of the ReduceMean operator. |
| OH_NN_REDUCE_MEAN_COEFF12+ | Used when the tensor is used as the **coeff** parameter of the ReduceMean operator. |
| OH_NN_REDUCE_PROD_REDUCE_TO_END12+ | Used when the tensor is used as the **reduceToEnd** parameter of the ReduceProd operator. |
| OH_NN_REDUCE_PROD_COEFF12+ | Used when the tensor is used as the **coeff** parameter of the ReduceProd operator. |
| OH_NN_REDUCE_ALL_REDUCE_TO_END12+ | Used when the tensor is used as the **reduceToEnd** parameter of the ReduceAll operator. |
| OH_NN_REDUCE_ALL_COEFF12+ | Used when the tensor is used as the **coeff** parameter of the ReduceAll operator. |
| OH_NN_TOP_K_AXIS12+ | Used when the tensor is used as the **axis** parameter of the TopK operator. |
| OH_NN_ARG_MAX_TOP_K12+ | Used when the tensor is used as the **topK** parameter of the ArgMax operator. |
| OH_NN_ARG_MAX_OUT_MAX_VALUE12+ | Used when the tensor is used as the **outMaxValue** parameter of the ArgMax operator. |
| OH_NN_QUANT_DTYPE_CAST_AXIS12+ | Used when the tensor is used as the **axis** parameter of the QuantDTypeCast operator. |
| OH_NN_SLICE_AXES12+ | Used when the tensor is used as the **axes** parameter of the Slice operator. |
| OH_NN_TILE_DIMS12+ | Used when the tensor is used as the **dims** parameter of the Tile operator. |
| OH_NN_CROP_AXIS12+ | Used when the tensor is used as the **axis** parameter of the Crop operator. |
| OH_NN_CROP_OFFSET12+ | Used when the tensor is used as the **offset** parameter of the Crop operator. |
| OH_NN_DETECTION_POST_PROCESS_INPUT_SIZE12+ | Used when the tensor is used as the **inputSize** parameter of the DetectionPostProcess operator. |
| OH_NN_DETECTION_POST_PROCESS_SCALE12+ | Used when the tensor is used as the **scale** parameter of the DetectionPostProcess operator. |
| OH_NN_DETECTION_POST_PROCESS_NMS_IOU_THRESHOLD12+ | Used when the tensor is used as the **nmsIouThreshold** parameter of the DetectionPostProcess operator. |
| OH_NN_DETECTION_POST_PROCESS_NMS_SCORE_THRESHOLD12+ | Used when the tensor is used as the **nmsScoreThreshold** parameter of the DetectionPostProcess operator. |
| OH_NN_DETECTION_POST_PROCESS_MAX_DETECTIONS12+ | Used when the tensor is used as the **maxDetections** parameter of the DetectionPostProcess operator. |
| OH_NN_DETECTION_POST_PROCESS_DETECTIONS_PER_CLASS12+ | Used when the tensor is used as the **preClass** parameter of the DetectionPostProcess operator. |
| OH_NN_DETECTION_POST_PROCESS_MAX_CLASSES_PER_DETECTION12+ | Used when the tensor is used as the **maxClassPreDetection** parameter of the DetectionPostProcess operator. |
| OH_NN_DETECTION_POST_PROCESS_NUM_CLASSES12+ | Used when the tensor is used as the **numClasses** parameter of the DetectionPostProcess operator. |
| OH_NN_DETECTION_POST_PROCESS_USE_REGULAR_NMS12+ | Used when the tensor is used as the **useRegularNms** parameter of the DetectionPostProcess operator. |
| OH_NN_DETECTION_POST_PROCESS_OUT_QUANTIZED12+ | Used when the tensor is used as the **outQuantized** parameter of the DetectionPostProcess operator. |
| OH_NN_L2_NORMALIZE_AXIS12+ | Used when the tensor is used as the **axis** parameter of the L2Normalize operator. |
| OH_NN_L2_NORMALIZE_EPSILON12+ | Used when the tensor is used as the **epslion** parameter of the L2Normalize operator. |
| OH_NN_L2_NORMALIZE_ACTIVATION_TYPE12+ | Used when the tensor is used as the **activationType** parameter of the L2Normalize operator. |
| OH_NN_LOG_SOFTMAX_AXIS12+ | Used when the tensor is used as the **axis** parameter of the LogSoftmax operator. |
| OH_NN_LRN_DEPTH_RADIUS12+ | Used when the tensor is used as the **depthRadius** parameter of the LRN operator. |
| OH_NN_LRN_BIAS12+ | Used when the tensor is used as the **bias** parameter of the LRN operator. |
| OH_NN_LRN_ALPHA12+ | Used when the tensor is used as the **alpha** parameter of the LRN operator. |
| OH_NN_LRN_BETA12+ | Used when the tensor is used as the **beta** parameter of the LRN operator. |
| OH_NN_LRN_NORM_REGION12+ | Used when the tensor is used as the **normRegion** parameter of the LRN operator. |
| OH_NN_SPACE_TO_DEPTH_BLOCK_SIZE12+ | Used when the tensor is used as the **blockSize** parameter of the SpaceToDepth operator.|
| OH_NN_REDUCE_MAX_KEEP_DIMS12+ | Used when the tensor is used as the **keepDims** parameter of the ReduceMax operator. |
| OH_NN_REDUCE_MAX_REDUCE_TO_END12+ | Used when the tensor is used as the **reduceToEnd** parameter of the ReduceMax operator. |
| OH_NN_REDUCE_MAX_COEFF12+ | Used when the tensor is used as the **coeff** parameter of the ReduceMax operator. |
| OH_NN_REDUCE_MIN_KEEP_DIMS12+ | Used when the tensor is used as the **keepDims** parameter of the ReduceMin operator. |
| OH_NN_REDUCE_MIN_REDUCE_TO_END12+ | Used when the tensor is used as the **reduceToEnd** parameter of the ReduceMin operator. |
| OH_NN_REDUCE_MIN_COEFF12+ | Used when the tensor is used as the **coeff** parameter of the ReduceMin operator. |
| OH_NN_REDUCE_SUM_KEEP_DIMS12+ | Used when the tensor is used as the **keepDims** parameter of the ReduceSum operator. |
| OH_NN_REDUCE_SUM_REDUCE_TO_END12+ | Used when the tensor is used as the **reduceToEnd** parameter of the ReduceSum operator. |
| OH_NN_REDUCE_SUM_COEFF12+ | Used when the tensor is used as the **coeff** parameter of the ReduceSum operator. |
| OH_NN_REDUCE_L2_KEEP_DIMS12+ | Used when the tensor is used as the **keepDims** parameter of the ReduceL2 operator. |
| OH_NN_REDUCE_L2_REDUCE_TO_END12+ | Used when the tensor is used as the **reduceToEnd** parameter of the ReduceL2 operator. |
| OH_NN_REDUCE_L2_COEFF12+ | Used when the tensor is used as the **coeff** parameter of the ReduceL2 operator. |
## Function Description
### OH_NNCompilation_AddExtensionConfig()
```
OH_NN_ReturnCode OH_NNCompilation_AddExtensionConfig (OH_NNCompilation *compilation, const char *configName, const void *configValue, const size_t configValueSize )
```
**Description**
Adds extended configurations for custom device attributes.
Some devices have their own attributes, which have not been enabled in NNRt. This API helps you to set custom attributes for these devices. You need to obtain their names and values from the device vendor's documentation and add them to the model building instance. These attributes are passed directly to the device driver. If the device driver cannot parse the attributes, this API returns an error code.
After [OH_NNCompilation_Build](#oh_nncompilation_build) is called, **configName** and **configValue** can be released.
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| compilation | Pointer to the [OH_NNCompilation](#oh_nncompilation) instance.|
| configName | Configuration name.|
| configValue | Configured value.|
| configValueSize | Size of the configured value, in bytes.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNCompilation_Build()
```
OH_NN_ReturnCode OH_NNCompilation_Build (OH_NNCompilation *compilation)
```
**Description**
Performs model building.
After the build configuration is complete, call this API to start model building. The model building instance pushes the model and build options to the device for building. After this API is called, additional build operations cannot be performed. If [OH_NNCompilation_SetDevice](#oh_nncompilation_setdevice), [OH_NNCompilation_SetCache](#oh_nncompilation_setcache), [OH_NNCompilation_SetPerformanceMode](#oh_nncompilation_setperformancemode), [OH_NNCompilation_SetPriority](#oh_nncompilation_setpriority), or [OH_NNCompilation_EnableFloat16](#oh_nncompilation_enablefloat16) is called, **OH_NN_OPERATION_FORBIDDEN** is returned.
**Since**: 9
**Parameters**
| Name| Description|
| -------- | -------- |
| compilation | Pointer to the [OH_NNCompilation](#oh_nncompilation) instance.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNCompilation_Construct()
```
OH_NNCompilation *OH_NNCompilation_Construct (const OH_NNModel *model)
```
**Description**
Creates a model building instance of the [OH_NNCompilation](#oh_nncompilation) type.
After the OH_NNModel module completes model construction, APIs provided by the OH_NNCompilation module pass the model to underlying device for building. This API creates an [OH_NNCompilation](#oh_nncompilation) instance based on the passed [OH_NNModel](#oh_nnmodel) instance. The [OH_NNCompilation_SetDevice](#oh_nncompilation_setdevice) API is called to specify the device for model building, and the [OH_NNCompilation_Build](#oh_nncompilation_build) API is then called to complete model building.
In addition to computing device selection, the OH_NNCompilation module supports features such as model cache, performance preference, priority setting, and float16 computing, which can be implemented by the following APIs:
[OH_NNCompilation_SetCache](#oh_nncompilation_setcache)
[OH_NNCompilation_SetPerformanceMode](#oh_nncompilation_setperformancemode)
[OH_NNCompilation_SetPriority](#oh_nncompilation_setpriority)
[OH_NNCompilation_EnableFloat16](#oh_nncompilation_enablefloat16)
After this API is called to create [OH_NNCompilation](#oh_nncompilation), the [OH_NNModel](#oh_nnmodel) instance can be released.
**Since**: 9
**Parameters**
| Name| Description|
| -------- | -------- |
| model | Pointer to the [OH_NNModel](#oh_nnmodel) instance.|
**Returns**
Pointer to the [OH_NNCompilation](#oh_nncompilation) instance. If the operation fails, **NULL** is returned.
### OH_NNCompilation_ConstructForCache()
```
OH_NNCompilation *OH_NNCompilation_ConstructForCache ()
```
**Description**
Creates an empty model building instance for later recovery from the model cache.
For details about the model cache, see [OH_NNCompilation_SetCache](#oh_nncompilation_setcache).
The time required for model recovery from the model cache is less than the time required for building using [OH_NNModel](#oh_nnmodel).
Call [OH_NNCompilation_SetCache](#oh_nncompilation_setcache) or [OH_NNCompilation_ImportCacheFromBuffer](#oh_nncompilation_importcachefrombuffer), and then call [OH_NNCompilation_Build](#oh_nncompilation_build) to complete model recovery.
**Since**: 11
**Returns**
Pointer to the [OH_NNCompilation](#oh_nncompilation) instance. If the operation fails, **NULL** is returned.
### OH_NNCompilation_ConstructWithOfflineModelBuffer()
```
OH_NNCompilation *OH_NNCompilation_ConstructWithOfflineModelBuffer (const void *modelBuffer, size_t modelSize )
```
**Description**
Creates a model building instance based on the offline model buffer.
This API conflicts with the one for transferring the path of the online or offline model building file. You can select only one of the three build APIs.
**NOTE**
The returned [OH_NNCompilation](#oh_nncompilation) instance only saves the **modelBuffer** pointer in it, but does not copy its data. The modelBuffer should not be released before the [OH_NNCompilation](#oh_nncompilation) instance is destroyed.
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| modelBuffer | Memory for storing offline model files.|
| modelSize | Memory size of the offline model.|
**Returns**
Pointer to the [OH_NNCompilation](#oh_nncompilation) instance. If the operation fails, **NULL** is returned.
### OH_NNCompilation_ConstructWithOfflineModelFile()
```
OH_NNCompilation *OH_NNCompilation_ConstructWithOfflineModelFile (const char *modelPath)
```
**Description**
Creates a model building instance based on an offline model file.
This API conflicts with the one for transferring the memory of the online or offline model building file. You can select only one of the three build APIs.
An offline model is a model type built offline by the model converter provided by the device vendor. Therefore, an offline model can be used only on a specified device. However, the build time of an offline model is usually far shorter than that of the image composition instance [OH_NNModel](#oh_nnmodel).
During development, offline build needs to be performed and offline models need to be deployed in application packages.
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| modelPath | Path of the offline model file.|
**Returns**
Pointer to the [OH_NNCompilation](#oh_nncompilation) instance. If the operation fails, **NULL** is returned.
### OH_NNCompilation_Destroy()
```
void OH_NNCompilation_Destroy (OH_NNCompilation **compilation)
```
**Description**
Destroys a model building instance of the [OH_NNCompilation](#oh_nncompilation) type.
This API needs to be called to destroy the model building instances created by calling [OH_NNCompilation_Construct](#oh_nncompilation_construct), [OH_NNCompilation_ConstructWithOfflineModelFile](#oh_nncompilation_constructwithofflinemodelfile), [OH_NNCompilation_ConstructWithOfflineModelBuffer](#oh_nncompilation_constructwithofflinemodelbuffer) and [OH_NNCompilation_ConstructForCache](#oh_nncompilation_constructforcache).
If **compilation** or **\*compilation** is a null pointer, this API only prints warning logs but does not perform the destruction operation.
**Since**: 9
**Parameters**
| Name| Description|
| -------- | -------- |
| compilation | Level-2 pointer to the [OH_NNCompilation](#oh_nncompilation) instance. After the model building instance is destroyed, this API sets **\*compilation** to a null pointer.|
### OH_NNCompilation_EnableFloat16()
```
OH_NN_ReturnCode OH_NNCompilation_EnableFloat16 (OH_NNCompilation *compilation, bool enableFloat16 )
```
**Description**
Enables float16 for computing.
By default, the floating-point model uses float32 for computing. If this API is called on a device that supports float16, floating-point model that supports float32 will use float16 for computing, so to reduce memory usage and execution time.
This option is invalid for fixed-point models, for example, fixed-point models of the int8 type.
If this API is called on the device that does not support float16, the error code **OH_NN_UNAVAILABLE_DEVICE** is returned.
**Since**: 9
**Parameters**
| Name| Description|
| -------- | -------- |
| compilation | Pointer to the [OH_NNCompilation](#oh_nncompilation) instance.|
| enableFloat16 | Whether to enable float16. If this parameter is set to **true**, float16 inference is performed. If this parameter is set to **false**, float32 inference is performed.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNCompilation_ExportCacheToBuffer()
```
OH_NN_ReturnCode OH_NNCompilation_ExportCacheToBuffer (OH_NNCompilation *compilation, const void *buffer, size_t length, size_t *modelSize )
```
**Description**
Writes the model cache to the specified buffer.
For details about the model cache, see [OH_NNCompilation_SetCache](#oh_nncompilation_setcache).
Note: The model cache is the build result [OH_NNCompilation_Build](#oh_nncompilation_build). Therefore, this API must be called after [OH_NNCompilation_Build](#oh_nncompilation_build).
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| compilation | Pointer to the [OH_NNCompilation](#oh_nncompilation) instance.|
| buffer | Pointer to the given memory.|
| length | Memory length. |
| modelSize | Size of the model cache, in bytes.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNCompilation_ImportCacheFromBuffer()
```
OH_NN_ReturnCode OH_NNCompilation_ImportCacheFromBuffer (OH_NNCompilation *compilation, const void *buffer, size_t modelSize )
```
**Description**
Reads the model cache from the specified buffer.
For details about the model cache, see [OH_NNCompilation_SetCache](#oh_nncompilation_setcache).
After calling [OH_NNCompilation_ImportCacheFromBuffer](#oh_nncompilation_importcachefrombuffer), call [OH_NNCompilation_Build](#oh_nncompilation_build) to complete model recovery.
Note: The **compilation** instance stores the buffer pointer in the buffer, but does not copy its data. You cannot release the memory buffer before the **compilation** instance is destroyed.
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| compilation | Pointer to the [OH_NNCompilation](#oh_nncompilation) instance.|
| buffer | Pointer to the given memory.|
| modelSize | Size of the model cache, in bytes.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNCompilation_SetCache()
```
OH_NN_ReturnCode OH_NNCompilation_SetCache (OH_NNCompilation *compilation, const char *cachePath, uint32_t version )
```
**Description**
Sets the cache directory and version for model building.
On the device that supports model caching, a model can be saved as a cache file after being built at the device driver layer. The model can be directly read from the cache file in the next build, saving the rebuild time. This API performs different operations based on the model cache directory and version:
- If no file exists in the specified model cache directory, cache the built model to the directory and set the cache version to the value of **version**.
- If a complete cached file exists in the specified model cache directory, and its version number is equal to **version**, read the cached file in the directory and pass it to the underlying device to convert it into an executable model instance.
- If a complete cached file exists in the specified model cache directory, but its version is earlier than **version**, update the cached file. After the model is built on the underlying device, the cached file in the cache directory is overwritten and the version is updated to **version**.
- If a complete cached file exists in the specified model cache directory, but its version is later than **version**, the cached file is not read and the error code **OH_NN_INVALID_PARAMETER** is returned.
- If the cached file in the specified model cache directory is incomplete or you do not have the file access permission, the error code **OH_NN_INVALID_FILE** is returned.
- If the model cache directory does not exist or you do not have the file access permission, the error code **OH_NN_INVALID_PATH** is returned.
**Since**: 9
**Parameters**
| Name| Description|
| -------- | -------- |
| compilation | Pointer to the [OH_NNCompilation](#oh_nncompilation) instance.|
| cachePath | Directory for storing model cache files. This API creates model cache directories for different devices in the cachePath directory. You are advised to use a separate cache directory for each model.|
| version | Cached model version.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNCompilation_SetDevice()
```
OH_NN_ReturnCode OH_NNCompilation_SetDevice (OH_NNCompilation *compilation, size_t deviceID )
```
**Description**
Sets the device for model building and computing.
In the build phase, you need to specify the device for model building and computing. Call [OH_NNDevice_GetAllDevicesID](#oh_nndevice_getalldevicesid) to obtain available device IDs. Then, call [OH_NNDevice_GetType](#oh_nndevice_gettype) and [OH_NNDevice_GetType](#oh_nndevice_gettype) to obtain device information and pass target device IDs to this API for setting.
**Since**: 9
**Parameters**
| Name| Description|
| -------- | -------- |
| compilation | Pointer to the [OH_NNCompilation](#oh_nncompilation) instance.|
| deviceID | Device ID. If the value is **0**, the first device in the current device list is used by default.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNCompilation_SetPerformanceMode()
```
OH_NN_ReturnCode OH_NNCompilation_SetPerformanceMode (OH_NNCompilation *compilation, OH_NN_PerformanceMode performanceMode )
```
**Description**
Sets the performance mode for model computing.
NNRt allows you to set the performance mode for model computing to meet the requirements of low power consumption and ultimate performance. If this API is not called to set the performance mode in the build phase, the model building instance assigns the **OH_NN_PERFORMANCE_NONE** mode for the model by default. In this case, the device performs computing in the default performance mode.
If this API is called on a device that does not support setting of the performance mode, the error code **OH_NN_UNAVAILABLE_DEVICE** is returned.
**Since**: 9
**Parameters**
| Name| Description|
| -------- | -------- |
| compilation | Pointer to the [OH_NNCompilation](#oh_nncompilation) instance.|
| performanceMode | Performance mode for model computing. For details, see [OH_NN_PerformanceMode](#oh_nn_performancemode).|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNCompilation_SetPriority()
```
OH_NN_ReturnCode OH_NNCompilation_SetPriority (OH_NNCompilation *compilation, OH_NN_Priority priority )
```
**Description**
Sets the priority for model computing.
NNRt allows you to set computing priorities for models. The priorities apply only to models created by the process with the same UID. The settings will not affect models created by processes with different UIDs on different devices.
If this API is called on a device that does not support priority setting, the error code **OH_NN_UNAVAILABLE_DEVICE** is returned.
**Since**: 9
**Parameters**
| Name| Description|
| -------- | -------- |
| compilation | Pointer to the [OH_NNCompilation](#oh_nncompilation) instance.|
| priority | Priority for model computing. For details, see [OH_NN_Priority](#oh_nn_priority).|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNDevice_GetAllDevicesID()
```
OH_NN_ReturnCode OH_NNDevice_GetAllDevicesID (const size_t **allDevicesID, uint32_t *deviceCount )
```
**Description**
Obtains the ID of the device connected to NNRt.
Each device has a unique and fixed ID, which is returned through a uin32_t array.
When device IDs are returned through the size_t array, each element of the array is the ID of a single device. Internal managment is used for array memory. The data pointer remains valid before this API is called next time.
**Since**: 9
**Parameters**
| Name| Description|
| -------- | -------- |
| allDevicesID | Pointer to the **size_t** array. The input **\*allDevicesID** must be a null pointer. Otherwise, the error code **OH_NN_INVALID_PARAMETER** is returned.|
| deviceCount | Pointer of the uint32_t type, which is used to return the length of **\*allDevicesID**.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNDevice_GetName()
```
OH_NN_ReturnCode OH_NNDevice_GetName (size_t deviceID, const char **name )
```
**Description**
Obtains the name of the specified device.
**deviceID** specifies the device ID used to obtain the device name. You can obtain the device ID by calling [OH_NNDevice_GetAllDevicesID](#oh_nndevice_getalldevicesid). If the value of **deviceID** is **0**, the first device in the device list is used by default.
**\*name** is a C-style string ended with **'\0'**.
**\*name** must be a null pointer. Otherwise, the error code **OH_NN_INVALID_PARAMETER** is returned. For example, you should define **char\* deviceName = NULL**, and then pass **&deviceName** as an input parameter.
**Since**: 9
**Parameters**
| Name| Description|
| -------- | -------- |
| deviceID | Device ID. If the value of **deviceID** is **0**, the first device in the device list is used by default.|
| name | Pointer to the char array, which saves the returned device name.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNDevice_GetType()
```
OH_NN_ReturnCode OH_NNDevice_GetType (size_t deviceID, OH_NN_DeviceType *deviceType )
```
**Description**
Obtains the type of the specified device.
**deviceID** specifies the device ID used to obtain the device type. If the value of **deviceID** is **0**, the first device in the device list is used by default. Currently, the following device types are supported:
- * - **OH_NN_CPU**: CPU device.
- * - **OH_NN_GPU**: GPU device.
- * - **OH_NN_ACCELERATOR**: machine learning dedicated accelerator.
- * - **OH_NN_OTHERS**: other device types.
**Since**: 9
**Parameters**
| Name| Description|
| -------- | -------- |
| deviceID | Device ID. If the value of **deviceID** is **0**, the first device in the device list is used by default.|
| deviceType | Pointer to the [OH_NN_DeviceType](#oh_nn_devicetype) instance. The device type information is returned.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNExecutor_AllocateInputMemory()
```
OH_NN_Memory *OH_NNExecutor_AllocateInputMemory (OH_NNExecutor *executor, uint32_t inputIndex, size_t length )
```
**Description**
Applies for shared memory for a single model input on the device.
NNRt provides an API for proactively applying for shared memory on a device. Based on the specified executor and input index value, this API applies for the shared memory whose size is **length** on the device associated with a single input. Then, it returns the shared memory through the [OH_NN_Memory](_o_h___n_n___memory.md) instance.
**Since**: 9
**Parameters**
| Name| Description|
| -------- | -------- |
| executor | Pointer to the [OH_NNExecutor](#oh_nnexecutor) instance.|
| inputIndex | Input index value, which complies with the data input sequence for calling [OH_NNModel_SpecifyInputsAndOutputs](#oh_nnmodel_specifyinputsandoutputs). Assume that **inputIndices** is **{1, 5, 9}** when [OH_NNModel_SpecifyInputsAndOutputs](#oh_nnmodel_specifyinputsandoutputs) is called. When you apply for the input memory, set the value of this parameter to **{0, 1, 2}**.|
| length | Memory size to be applied for, in bytes.|
**Returns**
Pointer to the [OH_NN_Memory](_o_h___n_n___memory.md) instance. If the operation fails, **NULL** is returned.
### OH_NNExecutor_AllocateOutputMemory()
```
OH_NN_Memory *OH_NNExecutor_AllocateOutputMemory (OH_NNExecutor *executor, uint32_t outputIndex, size_t length )
```
**Description**
Applies for shared memory for a single model output on the device.
NNRt provides an API for proactively applying for shared memory on a device. Based on the specified executor and input index value, this API applies for the shared memory whose size is **length** on the device associated with a single input. Then, it returns the shared memory through the [OH_NN_Memory](_o_h___n_n___memory.md) instance.
**Since**: 9
**Parameters**
| Name| Description|
| -------- | -------- |
| executor | Pointer to the [OH_NNExecutor](#oh_nnexecutor) instance.|
| outputIndex | Output index value, index value, which complies with the data input sequence for calling [OH_NNModel_SpecifyInputsAndOutputs](#oh_nnmodel_specifyinputsandoutputs). Assume that **outputIndices** is **{4, 6, 8}** when [OH_NNModel_SpecifyInputsAndOutputs](#oh_nnmodel_specifyinputsandoutputs) is called. When you apply for the output memory, set the value of this parameter to **{0, 1, 2}**.|
| length | Memory size to be applied for, in bytes.|
**Returns**
Pointer to the [OH_NN_Memory](_o_h___n_n___memory.md) instance. If the operation fails, **NULL** is returned.
### OH_NNExecutor_Construct()
```
OH_NNExecutor *OH_NNExecutor_Construct (OH_NNCompilation *compilation)
```
**Description**
Creates an [OH_NNExecutor](#oh_nnexecutor) instance.
This API constructs a model inference executor for a device based on the specified [OH_NNCompilation](#oh_nncompilation) instance. Use [OH_NNExecutor_SetInput](#oh_nnexecutor_setinput) to set the model input data. After the input data is set, call [OH_NNExecutor_Run](#oh_nnexecutor_run) to perform inference and then call [OH_NNExecutor_SetOutput](#oh_nnexecutor_setoutput) to obtain the computing result.
After an [OH_NNExecutor](#oh_nnexecutor) instance is created through the [OH_NNCompilation](#oh_nncompilation) instance, destroy the [OH_NNCompilation](#oh_nncompilation) instance if it is is no longer needed.
**Since**: 9
**Parameters**
| Name| Description|
| -------- | -------- |
| compilation | Pointer to the [OH_NNCompilation](#oh_nncompilation) instance.|
**Returns**
Pointer to the [OH_NNExecutor](#oh_nnexecutor) instance. If the operation fails, **NULL** is returned.
### OH_NNExecutor_CreateInputTensorDesc()
```
NN_TensorDesc *OH_NNExecutor_CreateInputTensorDesc (const OH_NNExecutor *executor, size_t index )
```
**Description**
Creates the description of an input tensor based on the specified index value.
The description contains all types of attribute values of the tensor. If the value of **index** reaches or exceeds the number of input tensors, this API returns an error code. You can obtain the number of input tensors by calling [OH_NNExecutor_GetInputCount](#oh_nnexecutor_getinputcount).
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| executor | Pointer to the [OH_NNExecutor](#oh_nnexecutor) instance.|
| index | Index value of the input tensor.|
**Returns**
Pointer to the [NN_TensorDesc](#nn_tensordesc) instance. If the operation fails, **NULL** is returned.
### OH_NNExecutor_CreateOutputTensorDesc()
```
NN_TensorDesc *OH_NNExecutor_CreateOutputTensorDesc (const OH_NNExecutor *executor, size_t index )
```
**Description**
Creates the description of an output tensor based on the specified index value.
The description contains all types of attribute values of the tensor. If the value of **index** reaches or exceeds the number of output tensors, this API returns an error code. You can obtain the number of output tensors by calling [OH_NNExecutor_GetOutputCount](#oh_nnexecutor_getoutputcount).
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| executor | Pointer to the [OH_NNExecutor](#oh_nnexecutor) instance.|
| index | Index value of the output tensor.|
**Returns**
Pointer to the [NN_TensorDesc](#nn_tensordesc) instance. If the operation fails, **NULL** is returned.
### OH_NNExecutor_Destroy()
```
void OH_NNExecutor_Destroy (OH_NNExecutor **executor)
```
**Description**
Destroys an executor instance to release the memory occupied by it.
This API needs to be called to release the executor instance created by calling [OH_NNExecutor_Construct](#oh_nnexecutor_construct). Otherwise, memory leak will occur.
If **executor** or **\*executor** is a null pointer, this API only prints the warning log and does not execute the release logic.
**Since**: 9
**Parameters**
| Name| Description|
| -------- | -------- |
| executor | Level-2 pointer to the [OH_NNExecutor](#oh_nnexecutor) instance.|
### OH_NNExecutor_DestroyInputMemory()
```
void OH_NNExecutor_DestroyInputMemory (OH_NNExecutor *executor, uint32_t inputIndex, OH_NN_Memory **memory )
```
**Description**
Releases the input memory pointed by the [OH_NN_Memory](_o_h___n_n___memory.md) instance.
This API needs to be called to release the memory instance created by calling [OH_NNExecutor_AllocateInputMemory](#oh_nnexecutor_allocateinputmemory). Otherwise, memory leak will occur. The mapping between **inputIndex** and **memory** must be the same as that in memory instance creation.
If **memory** or **\*memory** is a null pointer, this API only prints the warning log and does not execute the release logic.
**Since**: 9
**Parameters**
| Name| Description|
| -------- | -------- |
| executor | Pointer to the [OH_NNExecutor](#oh_nnexecutor) instance.|
| inputIndex | Input index value, which complies with the data input sequence for calling [OH_NNModel_SpecifyInputsAndOutputs](#oh_nnmodel_specifyinputsandoutputs). Assume that **inputIndices** is **{1, 5, 9}** when [OH_NNModel_SpecifyInputsAndOutputs](#oh_nnmodel_specifyinputsandoutputs) is called. When you release the input memory, set the value of this parameter to **{0, 1, 2}**.|
| memory | Level-2 pointer to the [OH_NN_Memory](_o_h___n_n___memory.md) instance. After the shared memory is released, this API sets **\*memory** to a null pointer.|
### OH_NNExecutor_DestroyOutputMemory()
```
void OH_NNExecutor_DestroyOutputMemory (OH_NNExecutor *executor, uint32_t outputIndex, OH_NN_Memory **memory )
```
**Description**
Releases the output memory pointed by the [OH_NN_Memory](_o_h___n_n___memory.md) instance.
This API needs to be called to release the memory instance created by calling [OH_NNExecutor_AllocateOutputMemory](#oh_nnexecutor_allocateoutputmemory). Otherwise, memory leak will occur. The mapping between **outputIndex** and **memory** must be the same as that in memory instance creation.
If **memory** or **\*memory** is a null pointer, this API only prints the warning log and does not execute the release logic.
**Since**: 9
**Parameters**
| Name| Description|
| -------- | -------- |
| executor | Pointer to the [OH_NNExecutor](#oh_nnexecutor) instance.|
| outputIndex | Output index value, index value, which complies with the data input sequence for calling [OH_NNModel_SpecifyInputsAndOutputs](#oh_nnmodel_specifyinputsandoutputs). Assume that **outputIndices** is **{4, 6, 8}** when [OH_NNModel_SpecifyInputsAndOutputs](#oh_nnmodel_specifyinputsandoutputs) is called. When you release the output memory, set the value of this parameter to **{0, 1, 2}**.|
| memory | Level-2 pointer to the [OH_NN_Memory](_o_h___n_n___memory.md) instance. After the shared memory is released, this API sets **\*memory** to a null pointer.|
### OH_NNExecutor_GetInputCount()
```
OH_NN_ReturnCode OH_NNExecutor_GetInputCount (const OH_NNExecutor *executor, size_t *inputCount )
```
**Description**
Obtains the number of input tensors.
You can obtain the number of input tensors from **executor**, and then use [OH_NNExecutor_CreateInputTensorDesc](#oh_nnexecutor_createinputtensordesc) to create a tensor description based on the specified tensor index.
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| executor | Pointer to the [OH_NNExecutor](#oh_nnexecutor) instance.|
| inputCount | Number of returned input tensors.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNExecutor_GetInputDimRange()
```
OH_NN_ReturnCode OH_NNExecutor_GetInputDimRange (const OH_NNExecutor *executor, size_t index, size_t **minInputDims, size_t **maxInputDims, size_t *shapeLength )
```
**Description**
Obtains the dimension range of all input tensors.
If the input tensor has a dynamic shape, the dimension range supported by the tensor may vary according to device. You can call this API to obtain the dimension range supported by the current device. **\*minInputDims** saves the minimum dimension of the specified input tensor (the number of dimensions matches the shape), while **\*maxInputDims** saves the maximum dimension. For example, if an input tensor has a dynamic shape of [-1, -1, -1, 3], **\*minInputDims** may be [1, 10, 10, 3], and **\*maxInputDims** may be [100, 1024, 1024, 3].
Note: If the value of **index** reaches or exceeds the number of output tensors, this API returns an error code. You can obtain the number of input tensors by calling [OH_NNExecutor_GetInputCount](#oh_nnexecutor_getinputcount).
As output parameters, **\*minInputDims** and **\*maxInputDims** cannot be null pointers. Otherwise, an error is returned. For example, you should define **int32_t\* minInDims = NULL**, and then pass **&minInDims** as a parameter.
You do not need to release the memory of **\*minInputDims** and **\*maxInputDims**. It is released with **executor**.
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| executor | Pointer to the [OH_NNExecutor](#oh_nnexecutor) instance.|
| index | Index value of the input tensor.|
| minInputDims | Pointer to the returned array, which saves the minimum dimension of the specified input tensor (the number of dimensions matches the shape).|
| maxInputDims | Pointer to the returned array, which saves the maximum dimension of the specified input tensor (the number of dimensions matches the shape).|
| shapeLength | Number of dimensions of the returned input tensor, which is the same as the shape.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNExecutor_GetOutputCount()
```
OH_NN_ReturnCode OH_NNExecutor_GetOutputCount (const OH_NNExecutor *executor, size_t *outputCount )
```
**Description**
Obtains the number of output tensors.
You can obtain the number of output tensors from **executor**, and then use [OH_NNExecutor_CreateOutputTensorDesc](#oh_nnexecutor_createoutputtensordesc) to create a tensor description based on the specified tensor index.
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| executor | Pointer to the [OH_NNExecutor](#oh_nnexecutor) instance.|
| outputCount | Number of returned output tensors.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNExecutor_GetOutputShape()
```
OH_NN_ReturnCode OH_NNExecutor_GetOutputShape (OH_NNExecutor *executor, uint32_t outputIndex, int32_t **shape, uint32_t *shapeLength )
```
**Description**
Obtains the dimension information about the output tensor.
You can use this API to obtain information about the specified output dimension and number of dimensions after a single inference is performed by calling [OH_NNExecutor_Run](#oh_nnexecutor_run). It is commonly used in dynamic shape input and output scenarios.
Note: If the value of **outputIndex** reaches or exceeds the number of output tensors, an error code is returned. You can obtain the number of output tensors by calling [OH_NNExecutor_GetOutputCount](#oh_nnexecutor_getoutputcount).
As an output parameter, **\*shape** cannot be a null pointer. Otherwise, an error is returned. For example, you should define **int32_t\* tensorShape = NULL** and pass **&tensorShape** as a parameter.
You do not need to release the memory of **shape**. It is released with **executor**.
**Since**: 9
**Parameters**
| Name| Description|
| -------- | -------- |
| executor | Pointer to the [OH_NNExecutor](#oh_nnexecutor) instance.|
| outputIndex | Output index value, which is the same as the sequence of the output data when [OH_NNModel_SpecifyInputsAndOutputs](#oh_nnmodel_specifyinputsandoutputs) is called. Assume that **outputIndices** is {4, 6, 8} when [OH_NNModel_SpecifyInputsAndOutputs](#oh_nnmodel_specifyinputsandoutputs) is called. When you obtain information about the output dimension, set the value of this parameter to {0, 1, 2}.|
| shape | Pointer to the int32_t array. The value of each element in the array is the length of the output tensor in each dimension.|
| shapeLength | Pointer to the uint32_t type. The number of output dimensions is returned.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNExecutor_Run()
```
OH_NN_ReturnCode OH_NNExecutor_Run (OH_NNExecutor *executor)
```
**Description**
Executes model inference.
This API performs end-to-end model inference and computing on the device associated with the executor.
**Since**: 9
**Parameters**
| Name| Description|
| -------- | -------- |
| executor | Pointer to the [OH_NNExecutor](#oh_nnexecutor) instance.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNExecutor_RunAsync()
```
OH_NN_ReturnCode OH_NNExecutor_RunAsync (OH_NNExecutor *executor, NN_Tensor *inputTensor[], size_t inputCount, NN_Tensor *outputTensor[], size_t outputCount, int32_t timeout, void *userData )
```
**Description**
Performs asynchronous inference.
You need to create the input and output tensors by calling [OH_NNTensor_Create](#oh_nntensor_create), [OH_NNTensor_CreateWithSize](#oh_nntensor_createwithsize), or [OH_NNTensor_CreateWithFd](#oh_nntensor_createwithfd). Then, call [OH_NNTensor_GetDataBuffer](#oh_nntensor_getdatabuffer) o obtain the pointer to the tensor data and copies the input data to it. The executor performs model inference, generates the inference result, and writes the result to the output tensor.
If the output tensor has a dynamic shape, you can obtain the actual shape of the output tensor by calling [OH_NNExecutor_GetOutputShape](#oh_nnexecutor_getoutputshape). Alternatively, obtain the tensor description from the input tensor by calling [OH_NNTensor_GetTensorDesc](#oh_nntensor_gettensordesc), and then obtain the actual shape by calling [OH_NNTensorDesc_GetShape](#oh_nntensordesc_getshape).
This API works in non-blocking mode and returns the result immediately after being called. You can obtain the inference result and execution return status through the [NN_OnRunDone](#nn_onrundone) callback. If the device driver service stops abnormally during execution, you can use the [NN_OnServiceDied](#nn_onservicedied) callback for exception processing.
You can set the [NN_OnRunDone](#nn_onrundone) and [NN_OnServiceDied](#nn_onservicedied) callbacks by calling [OH_NNExecutor_SetOnRunDone](#oh_nnexecutor_setonrundone) and [OH_NNExecutor_SetOnServiceDied](#oh_nnexecutor_setonservicedied).
If the inference times out, it is terminated immediately and the error code **OH_NN_TIMEOUT** is returned through the [NN_OnRunDone](#nn_onrundone) callback.
**userData** is the identifier used to distinguish different asynchronous inferences and is returned as the first parameter in the callback. You can use any data that can distinguish different inferences as the identifier.
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| executor | Pointer to the [OH_NNExecutor](#oh_nnexecutor) instance.|
| inputTensor | Array of input tensors.|
| inputCount | Number of input tensors.|
| outputTensor | Array of output tensors.|
| outputCount | Number of output tensors.|
| timeout | Timeout interval of asynchronous inference, in ms.|
| userData | Identifier of asynchronous inference.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNExecutor_RunSync()
```
OH_NN_ReturnCode OH_NNExecutor_RunSync (OH_NNExecutor *executor, NN_Tensor *inputTensor[], size_t inputCount, NN_Tensor *outputTensor[], size_t outputCount )
```
**Description**
Performs synchronous inference.
You need to create the input and output tensors by calling [OH_NNTensor_Create](#oh_nntensor_create), [OH_NNTensor_CreateWithSize](#oh_nntensor_createwithsize), or [OH_NNTensor_CreateWithFd](#oh_nntensor_createwithfd). Then, call [OH_NNTensor_GetDataBuffer](#oh_nntensor_getdatabuffer) o obtain the pointer to the tensor data and copies the input data to it. The executor performs model inference, generates the inference result, and writes the result to the output tensor.
If the output tensor has a dynamic shape, you can obtain the actual shape of the output tensor by calling [OH_NNExecutor_GetOutputShape](#oh_nnexecutor_getoutputshape). Alternatively, obtain the tensor description from the input tensor by calling [OH_NNTensor_GetTensorDesc](#oh_nntensor_gettensordesc), and then obtain the actual shape by calling [OH_NNTensorDesc_GetShape](#oh_nntensordesc_getshape).
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| executor | Pointer to the [OH_NNExecutor](#oh_nnexecutor) instance.|
| inputTensor | Array of input tensors.|
| inputCount | Number of input tensors.|
| outputTensor | Array of output tensors.|
| outputCount | Number of output tensors.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNExecutor_SetInput()
```
OH_NN_ReturnCode OH_NNExecutor_SetInput (OH_NNExecutor *executor, uint32_t inputIndex, const OH_NN_Tensor *tensor, const void *dataBuffer, size_t length )
```
**Description**
Sets the data for a single model input.
This API copies the data whose length is specified by **length** (in bytes) in **dataBuffer** to the shared memory of the underlying device. **inputIndex** specifies the input to be set and **tensor** sets tensor information such as the shape, type, and quantization parameters.
NNRt supports models with dynamical shape input. For fixed shape input and dynamic shape input scenarios, this API uses different processing policies.
- - Fixed shape input: The attributes of **tensor** must be the same as those of the tensor added by calling [OH_NNModel_AddTensor](#oh_nnmodel_addtensor) in the build phase.
- - Dynamic shape input: In the composition phase, because the shape is not fixed, each value in **tensor.dimensions** must be greater than **0** in the API calls to determine the shape input in the computing phase. When setting the shape, you can modify only the dimension whose value is **-1**. Assume that **[-1, 224, 224, 3]** is input as the the dimension of A in the composition phase. When this API is called, you can only change the size of the first dimension, for example, to [3, 224, 224, 3]. If other dimensions are adjusted, **OH_NN_INVALID_PARAMETER** is returned.
**Since**: 9
**Parameters**
| Name| Description|
| -------- | -------- |
| executor | Pointer to the [OH_NNExecutor](#oh_nnexecutor) instance.|
| inputIndex | Input index value, which complies with the data input sequence for calling [OH_NNModel_SpecifyInputsAndOutputs](#oh_nnmodel_specifyinputsandoutputs). Assume that **inputIndices** is **{1, 5, 9}** when [OH_NNModel_SpecifyInputsAndOutputs](#oh_nnmodel_specifyinputsandoutputs) is called. When you set the input data, set the value of this parameter to **{0, 1, 2}**.|
| tensor | Tensor corresponding to the input data.|
| dataBuffer | Pointer to the input data.|
| length | Length of the data memory, in bytes.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNExecutor_SetInputWithMemory()
```
OH_NN_ReturnCode OH_NNExecutor_SetInputWithMemory (OH_NNExecutor *executor, uint32_t inputIndex, const OH_NN_Tensor *tensor, const OH_NN_Memory *memory )
```
**Description**
Shared memory pointed by the [OH_NN_Memory](_o_h___n_n___memory.md) instance for a single model input.
In the scenario where the memory needs to be managed by yourself, this API binds the execution input to the [OH_NN_Memory](_o_h___n_n___memory.md) memory instance. During computing, the underlying device reads the input data from the shared memory pointed by the memory instance. By using this API, you can implement concurrent execution of input setting, computing, and read to improve the data flow inference efficiency.
**Since**: 9
**Parameters**
| Name| Description|
| -------- | -------- |
| executor | Pointer to the [OH_NNExecutor](#oh_nnexecutor) instance.|
| inputIndex | Input index value, which complies with the data input sequence for calling [OH_NNModel_SpecifyInputsAndOutputs](#oh_nnmodel_specifyinputsandoutputs). Assume that **inputIndices** is {1, 5, 9} when [OH_NNModel_SpecifyInputsAndOutputs](#oh_nnmodel_specifyinputsandoutputs) is called. When you set the input shared memory, set the value of this parameter to {0, 1, 2}.|
| tensor | Pointer to [OH_NN_Tensor](_o_h___n_n___tensor.md), which is used to set the tensor corresponding to a single input.|
| memory | Pointer that points to [OH_NN_Memory](_o_h___n_n___memory.md).|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNExecutor_SetOnRunDone()
```
OH_NN_ReturnCode OH_NNExecutor_SetOnRunDone (OH_NNExecutor *executor, NN_OnRunDone onRunDone )
```
**Description**
Sets the callback processing function invoked when the asynchronous inference ends.
For the definition of the callback function, see [NN_OnRunDone](#nn_onrundone).
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| executor | Pointer to the [OH_NNExecutor](#oh_nnexecutor) instance.|
| onRunDone | Handle of the callback function [NN_OnRunDone](#nn_onrundone)|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNExecutor_SetOnServiceDied()
```
OH_NN_ReturnCode OH_NNExecutor_SetOnServiceDied (OH_NNExecutor *executor, NN_OnServiceDied onServiceDied )
```
**Description**
Sets the callback processing function invoked when the device driver service terminates unexpectedly during asynchronous inference.
For the definition of the callback function, see [NN_OnServiceDied](#nn_onservicedied).
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| executor | Pointer to the [OH_NNExecutor](#oh_nnexecutor) instance.|
| onServiceDied | Callback function handle [NN_OnServiceDied](#nn_onservicedied).|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNExecutor_SetOutput()
```
OH_NN_ReturnCode OH_NNExecutor_SetOutput (OH_NNExecutor *executor, uint32_t outputIndex, void *dataBuffer, size_t length )
```
**Description**
Sets the memory for a single model output.
This method binds the buffer pointed by **dataBuffer** to the output specified by **outputIndex**. The length of the buffer is specified by **length**.
After [OH_NNExecutor_Run](#oh_nnexecutor_run) is called to complete a single model inference, NNRt compares the length of the buffer pointed by **dataBuffer** with the length of the output data and returns different results based on the actual situation.
- If the memory size is greater than or equal to the data length, the API copies the inference result to the memory and returns **OH_NN_SUCCESS**. You can read the inference result from **dataBuffer**.
- If the memory size is less than the data length, this API returns the error code **OH_NN_INVALID_PARAMETER** and generates a log indicating that the memory size is too small.
**Since**: 9
**Parameters**
| Name| Description|
| -------- | -------- |
| executor | Pointer to the [OH_NNExecutor](#oh_nnexecutor) instance.|
| outputIndex | Output index value, which is the same as the sequence of the output data when [OH_NNModel_SpecifyInputsAndOutputs](#oh_nnmodel_specifyinputsandoutputs) is called. Assume that **outputIndices** is **{4, 6, 8}** when [OH_NNModel_SpecifyInputsAndOutputs](#oh_nnmodel_specifyinputsandoutputs) is called. When you set the output memory, set the value of this parameter to **{0, 1, 2}**.|
| dataBuffer | Pointer to the output data.|
| length | Length of the data memory, in bytes.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNExecutor_SetOutputWithMemory()
```
OH_NN_ReturnCode OH_NNExecutor_SetOutputWithMemory (OH_NNExecutor *executor, uint32_t outputIndex, const OH_NN_Memory *memory )
```
**Description**
Shared memory pointed by the [OH_NN_Memory](_o_h___n_n___memory.md) instance for a single model output.
In the scenario where the memory needs to be managed by yourself, this API binds the execution output to the [OH_NN_Memory](_o_h___n_n___memory.md) memory instance. During computing, the underlying device writes the computing result to the shared memory pointed by the memory instance. By using this API, you can implement concurrent execution of input setting, computing, and read to improve the data flow inference efficiency.
**Since**: 9
**Parameters**
| Name| Description|
| -------- | -------- |
| executor | Pointer to the executor.|
| outputIndex | Output index value, which is the same as the sequence of the output data when [OH_NNModel_SpecifyInputsAndOutputs](#oh_nnmodel_specifyinputsandoutputs) is called. Assume that **outputIndices** is {4, 6, 8} when [OH_NNModel_SpecifyInputsAndOutputs](#oh_nnmodel_specifyinputsandoutputs) is called. When you set the output shared memory, set the value of this parameter to {0, 1, 2}.|
| memory | Pointer that points to [OH_NN_Memory](_o_h___n_n___memory.md).|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNModel_AddOperation()
```
OH_NN_ReturnCode OH_NNModel_AddOperation (OH_NNModel *model, OH_NN_OperationType op, const OH_NN_UInt32Array *paramIndices, const OH_NN_UInt32Array *inputIndices, const OH_NN_UInt32Array *outputIndices )
```
**Description**
Adds an operator to a model instance.
You can use this API to add an operator to a model instance. The operator type is specified by **op**, and the operator parameters, inputs, and outputs are specified by **paramIndices**, **inputIndices**, and **outputIndices** respectively. This API verifies the attributes of operator parameters and the number of input and output parameters. These attributes must be correctly set when [OH_NNModel_AddTensorToModel](#oh_nnmodel_addtensortomodel) is called to add tensors. For details about the expected parameters, input attributes, and output attributes of each operator, see [OH_NN_OperationType](#oh_nn_operationtype).
**paramIndices**, **inputIndices**, and **outputIndices** store index values of tensors. Index values are determined by the sequence in which tensors are added to the model. For details about how to add a tensor, see [OH_NNModel_AddTensorToModel](#oh_nnmodel_addtensortomodel).
If unnecessary parameters are added for adding an operator, this API returns the error code **OH_NN_INVALID_PARAMETER**. If no operator parameter is set, the operator uses the default parameter value. For details about the default values, see [OH_NN_OperationType](#oh_nn_operationtype).
**Since**: 9
**Parameters**
| Name| Description|
| -------- | -------- |
| model | Pointer to the [OH_NNModel](#oh_nnmodel) instance.|
| op | Type of the operator to be added. For details, see [OH_NN_OperationType](#oh_nn_operationtype).|
| paramIndices | Pointer to the **OH_NN_UInt32Array** instance, which is used to set the parameter tensor index of the operator.|
| inputIndices | Pointer to the **OH_NN_UInt32Array** instance, specifying the input tensor index of the operator.|
| outputIndices | Pointer to the **OH_NN_UInt32Array** instance, which is used to set the output tensor index of the operator.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNModel_AddTensor()
```
OH_NN_ReturnCode OH_NNModel_AddTensor (OH_NNModel *model, const OH_NN_Tensor *tensor )
```
**Description**
Adds a tensor to a model instance.
The data node and operator parameters in the NNRt model are composed of tensors of the model. You can use this API to add tensors to a model instance based on the **tensor** parameter. The sequence of adding tensors is specified by the index value recorded in the model. The [OH_NNModel_SetTensorData](#oh_nnmodel_settensordata), [OH_NNModel_AddOperation](#oh_nnmodel_addoperation), and [OH_NNModel_SpecifyInputsAndOutputs](#oh_nnmodel_specifyinputsandoutputs) APIs specify tensors based on the index value.
NNRt supports input and output of dynamic shapes. When adding a data node with a dynamic shape, you need to set the dimensions that support dynamic changes in **tensor.dimensions** to **-1**. For example, if **tensor.dimensions** of a four-dimensional tensor is set to **[1, -1, 2, 2]**, the second dimension supports dynamic changes.
**Since**: 9
**Parameters**
| Name| Description|
| -------- | -------- |
| model | Pointer to the [OH_NNModel](#oh_nnmodel) instance.|
| tensor | Pointer to the [OH_NN_Tensor](_o_h___n_n___tensor.md) tensor. The tensor specifies the attributes of the tensor added to the model instance.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNModel_AddTensorToModel()
```
OH_NN_ReturnCode OH_NNModel_AddTensorToModel (OH_NNModel *model, const NN_TensorDesc *tensorDesc )
```
**Description**
Adds a tensor to a model instance.
The data node and operator parameters in the NNRt model are composed of tensors of the model. This API adds tensors to a model instance based on [NN_TensorDesc](#nn_tensordesc). The sequence of adding tensors is specified by the index value recorded in the model. The [OH_NNModel_SetTensorData](#oh_nnmodel_settensordata), [OH_NNModel_AddOperation](#oh_nnmodel_addoperation), and [OH_NNModel_SpecifyInputsAndOutputs](#oh_nnmodel_specifyinputsandoutputs) APIs specify tensors based on the index value.
NNRt supports input and output of dynamic shapes. When adding a data node with a dynamic shape, you need to set the dimensions that support dynamic changes in **tensor.dimensions** to **-1**. For example, if **tensor.dimensions** of a four-dimensional tensor is set to **[1, -1, 2, 2]**, the second dimension supports dynamic changes.
**Since**: 9
**Parameters**
| Name| Description|
| -------- | -------- |
| model | Pointer to the [OH_NNModel](#oh_nnmodel) instance.|
| tensorDesc | Pointer to [NN_TensorDesc](#nn_tensordesc) tensor, which specifies the attributes of the tensor added to the model instance.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNModel_Construct()
```
OH_NNModel *OH_NNModel_Construct (void )
```
**Description**
Creates a model instance of the [OH_NNModel](#oh_nnmodel) type and constructs a model instance by using the APIs provided by **OH_NNModel**.
Before composition, call [OH_NNModel_Construct](#oh_nnmodel_construct) to create a model instance. Based on the model topology, call the [OH_NNModel_AddTensorToModel](#oh_nnmodel_addtensortomodel), [OH_NNModel_AddOperation](#oh_nnmodel_addoperation), and [OH_NNModel_SetTensorData](#oh_nnmodel_settensordata) APIs to fill in the data and operator nodes of the model, and then call [OH_NNModel_SpecifyInputsAndOutputs](#oh_nnmodel_specifyinputsandoutputs) to specify the input and output of the model. After the model topology is constructed, call [OH_NNModel_Finish](#oh_nnmodel_finish) to build the model.
After a model instance is used, destroy it by calling [OH_NNModel_Destroy](#oh_nnmodel_destroy) to avoid memory leak.
**Since**: 9
**Returns**
Pointer to the [OH_NNModel](#oh_nnmodel) instance. If the operation fails, **NULL** is returned.
### OH_NNModel_Destroy()
```
void OH_NNModel_Destroy (OH_NNModel **model)
```
**Description**
Destroys a model instance.
This API needs to be called to destroy the model instance created by calling [OH_NNModel_Construct](#oh_nnmodel_construct). Otherwise, memory leak will occur.
If **model** or **\*model** is a null pointer, this API only prints warning logs but does not perform the destruction operation.
**Since**: 9
**Parameters**
| Name| Description|
| -------- | -------- |
| model | Level-2 pointer to the [OH_NNModel](#oh_nnmodel) instance. After a model instance is destroyed, this API sets **\*model** to a null pointer.|
### OH_NNModel_Finish()
```
OH_NN_ReturnCode OH_NNModel_Finish (OH_NNModel *model)
```
**Description**
Completes model composition.
After the model topology is set up, call this API to indicate that the composition is complete. After this API is called, additional image composition cannot be performed. If [OH_NNModel_AddTensorToModel](#oh_nnmodel_addtensortomodel), [OH_NNModel_AddOperation](#oh_nnmodel_addoperation), [OH_NNModel_SetTensorData](#oh_nnmodel_settensordata), or [OH_NNModel_SpecifyInputsAndOutputs](#oh_nnmodel_specifyinputsandoutputs) is called, **OH_NN_OPERATION_FORBIDDEN** is returned.
Before calling **OH_NNModel_GetAvailableOperations** and **OH_NNCompilation_Construct**, you must call this API to complete composition.
**Since**: 9
**Parameters**
| Name| Description|
| -------- | -------- |
| model | Pointer to the [OH_NNModel](#oh_nnmodel) instance.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNModel_GetAvailableOperations()
```
OH_NN_ReturnCode OH_NNModel_GetAvailableOperations (OH_NNModel *model, size_t deviceID, const bool **isSupported, uint32_t *opCount )
```
**Description**
Checks whether all operators in a model are supported by the device. The result is indicated by a Boolean value.
Checks whether the underlying device supports operators in a model instance. The device is specified by **deviceID**, and the result is represented by the array pointed by **isSupported**. If the *i*th operator is supported, the value of **(\*isSupported)**[*i*] is **true**. Otherwise, the value is **false**.
After this API is successfully executed, **(*isSupported)** points to the bool array that records the operator support status. The operator quantity for the array length is the same as that for the model instance. The memory corresponding to this array is managed by NNRt and is automatically destroyed after the model instance is destroyed or this API is called again.
**Since**: 9
**Parameters**
| Name| Description|
| -------- | -------- |
| model | Pointer to the [OH_NNModel](#oh_nnmodel) instance.|
| deviceID | Device ID to be queried, which can be obtained by using [OH_NNDevice_GetAllDevicesID](#oh_nndevice_getalldevicesid).|
| isSupported | Pointer to the **OHHDRMetaData** array. The input **(\*isSupported)** must be a null pointer. Otherwise, **OH_NN_INVALID_PARAMETER** is returned.|
| opCount | Number of operators in a model instance, corresponding to the length of the **(\*isSupported)** array.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNModel_SetTensorData()
```
OH_NN_ReturnCode OH_NNModel_SetTensorData (OH_NNModel *model, uint32_t index, const void *dataBuffer, size_t length )
```
**Description**
Sets the tensor value.
For tensors with constant values (such as model weights), you need to use this API in the composition phase. The index value of a tensor is determined by the sequence in which the tensor is added to the model. For details about how to add a tensor, see [OH_NNModel_AddTensorToModel](#oh_nnmodel_addtensortomodel).
**Since**: 9
**Parameters**
| Name| Description|
| -------- | -------- |
| model | Pointer to the [OH_NNModel](#oh_nnmodel) instance.|
| index | Index value of a tensor.|
| dataBuffer | Pointer to the real data memory.|
| length | Length of the data memory.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNModel_SetTensorQuantParams()
```
OH_NN_ReturnCode OH_NNModel_SetTensorQuantParams (OH_NNModel *model, uint32_t index, NN_QuantParam *quantParam )
```
**Description**
Sets the quantization parameters of a tensor. For details, see [NN_QuantParam](#nn_quantparam).
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| model | Pointer to the [OH_NNModel](#oh_nnmodel) instance.|
| index | Index value of a tensor.|
| quantParam | Pointer to [NN_QuantParam](#nn_quantparam).|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNModel_SetTensorType()
```
OH_NN_ReturnCode OH_NNModel_SetTensorType (OH_NNModel *model, uint32_t index, OH_NN_TensorType tensorType )
```
**Description**
Sets the tensor type. For details, see [OH_NN_TensorType](#oh_nn_tensortype).
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| model | Pointer to the [OH_NNModel](#oh_nnmodel) instance.|
| index | Index value of a tensor.|
| tensorType | Tensor type.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNModel_SpecifyInputsAndOutputs()
```
OH_NN_ReturnCode OH_NNModel_SpecifyInputsAndOutputs (OH_NNModel *model, const OH_NN_UInt32Array *inputIndices, const OH_NN_UInt32Array *outputIndices )
```
**Description**
Sets an index value for the input and output tensors of a model.
A tensor must be specified as the end-to-end input and output of a model instance. After a tensor is set as the input or output tensor, you are not allowed to set the tensor data by calling [OH_NNModel_SetTensorData](#oh_nnmodel_settensordata). Instead, call **OH_NNExecutor** in the execution phase to set the input or output tensor data.
The index value of a tensor is determined by the sequence in which the tensor is added to the model. For details about how to add a tensor, see [OH_NNModel_AddTensorToModel](#oh_nnmodel_addtensortomodel).
Currently, the model input and output cannot be set asynchronously.
**Since**: 9
**Parameters**
| Name| Description|
| -------- | -------- |
| model | Pointer to the [OH_NNModel](#oh_nnmodel) instance.|
| inputIndices | Pointer to the **OH_NN_UInt32Array** instance, which is used to set the input tensor of the operator.|
| outputIndices | Pointer to the OH_NN_UInt32Array instance, which is used to set the output tensor of the operator.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNQuantParam_Create()
```
NN_QuantParam *OH_NNQuantParam_Create ()
```
**Description**
Creates an [NN_QuantParam](#nn_quantparam) instance.
After creating an [NN_QuantParam](#nn_quantparam) quantization parameter instance, set its attribute values by calling [OH_NNQuantParam_SetScales](#oh_nnquantparam_setscales), [OH_NNQuantParam_SetZeroPoints](#oh_nnquantparam_setzeropoints), or [OH_NNQuantParam_SetNumBits](#oh_nnquantparam_setnumbits), and pass it to [NN_Tensor](#nn_tensor) by calling [OH_NNModel_SetTensorQuantParams](#oh_nnmodel_settensorquantparams). Finally, call [OH_NNQuantParam_Destroy](#oh_nnquantparam_destroy) to destroy it to avoid memory leakage.
**Since**: 11
**Returns**
Pointer to the [NN_QuantParam](#nn_quantparam) instance. If the operation fails, **NULL** is returned.
### OH_NNQuantParam_Destroy()
```
OH_NN_ReturnCode OH_NNQuantParam_Destroy (NN_QuantParam **quantParams)
```
**Description**
Destroys an [NN_QuantParam](#nn_quantparam) instance.
After an [NN_QuantParam](#nn_quantparam) instance is no longer needed after being passed to [NN_Tensor](#nn_tensor), you need to destroy it to avoid memory leak.
If **quantParams** or **\*quantParams** is a null pointer, this API only prints warning logs but does not perform the destruction operation.
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| quantParams | Level-2 pointer to the [NN_QuantParam](#nn_quantparam) instance.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNQuantParam_SetNumBits()
```
OH_NN_ReturnCode OH_NNQuantParam_SetNumBits (NN_QuantParam *quantParams, const uint32_t *numBits, size_t quantCount )
```
**Description**
Sets the number of quantization bits for an [NN_QuantParam](#nn_quantparam) instance.
**quantCount** is the number of quantization parameters in the tensor. For example, for per-channel quantization, **quantCount** is the number of channels.
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| quantParams | Pointer to the [NN_QuantParam](#nn_quantparam) instance.|
| numBits | Array consisting of quantization bits of all quantization parameters in a tensor.|
| quantCount | Number of quantization parameters in a tensor.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNQuantParam_SetScales()
```
OH_NN_ReturnCode OH_NNQuantParam_SetScales (NN_QuantParam *quantParams, const double *scales, size_t quantCount )
```
**Description**
Sets the scaling coefficient for an [NN_QuantParam](#nn_quantparam) instance.
**quantCount** is the number of quantization parameters in the tensor. For example, for per-channel quantization, **quantCount** is the number of channels.
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| quantParams | Pointer to the [NN_QuantParam](#nn_quantparam) instance.|
| scales | Array consisting of scaling coefficients of all quantization parameters in the tensor.|
| quantCount | Number of quantization parameters in a tensor.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNQuantParam_SetZeroPoints()
```
OH_NN_ReturnCode OH_NNQuantParam_SetZeroPoints (NN_QuantParam *quantParams, const int32_t *zeroPoints, size_t quantCount )
```
**Description**
Sets the zero point for an [NN_QuantParam](#nn_quantparam) instance.
**quantCount** is the number of quantization parameters in the tensor. For example, for per-channel quantization, **quantCount** is the number of channels.
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| quantParams | Pointer to the [NN_QuantParam](#nn_quantparam) instance.|
| zeroPoints | Array consisting of zero points of all quantization parameters in a tensor.|
| quantCount | Number of quantization parameters in a tensor.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNTensor_Create()
```
NN_Tensor *OH_NNTensor_Create (size_t deviceID, NN_TensorDesc *tensorDesc )
```
**Description**
Creates an [NN_Tensor](#nn_tensor) instance from [NN_TensorDesc](#nn_tensordesc).
This API uses [OH_NNTensorDesc_GetByteSize](#oh_nntensordesc_getbytesize) to calculate the number of bytes of tensor data and allocate device memory for it. The device driver directly obtains tensor data in zero-copy mode.
Note: This API copies **tensorDesc** to [NN_Tensor](#nn_tensor). Therefore, if **tensorDesc** is no longer needed, destroy it by calling [OH_NNTensorDesc_Destroy](#oh_nntensordesc_destroy).
If the tensor shape is dynamic, an error code is returned.
**deviceID** indicates the selected device. If the value is **0**, the first device in the current device list is used by default.
**tensorDesc is mandatory**. If it is a null pointer, an error code is returned.
If the [NN_Tensor](#nn_tensor) instance is no longer needed, destroy it by calling [OH_NNTensor_Destroy](#oh_nntensor_destroy).
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| deviceID | Device ID. If the value is **0**, the first device in the current device list is used by default.|
| tensorDesc | Pointer to the [NN_TensorDesc](#nn_tensordesc) instance.|
**Returns**
Pointer to the [NN_Tensor](#nn_tensor) instance. If the operation fails, **NULL** is returned.
### OH_NNTensor_CreateWithFd()
```
NN_Tensor *OH_NNTensor_CreateWithFd (size_t deviceID, NN_TensorDesc *tensorDesc, int fd, size_t size, size_t offset )
```
**Description**
Creates an {\@Link NN_Tensor} instance based on the specified file descriptor of the shared memory and [NN_TensorDesc](#nn_tensordesc) instance.
This API reuses the shared memory corresponding to **fd**, which may source from another [NN_Tensor](#nn_tensor) instance. When the tensor created by calling [OH_NNTensor_Destroy](#oh_nntensor_destroy) is destroyed, the memory for storing the tensor data is not released.
Note: This API copies **tensorDesc** to [NN_Tensor](#nn_tensor). Therefore, if **tensorDesc** is no longer needed, destroy it by calling [OH_NNTensorDesc_Destroy](#oh_nntensordesc_destroy).
**deviceID** indicates the selected device. If the value is **0**, the first device in the current device list is used by default.
**tensorDesc** is mandatory. If the pointer is null, an error code is returned.
If the [NN_Tensor](#nn_tensor) instance is no longer needed, destroy it by calling [OH_NNTensor_Destroy](#oh_nntensor_destroy).
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| deviceID | Device ID. If the value is **0**, the first device in the current device list is used by default.|
| tensorDesc | Pointer to the [NN_TensorDesc](#nn_tensordesc) instance.|
| fd | **fd** of the shared memory to be used.|
| size | Size of the shared memory to be used.|
| offset | Offset of the shared memory to be used.|
**Returns**
Pointer to the [NN_Tensor](#nn_tensor) instance. If the operation fails, **NULL** is returned.
### OH_NNTensor_CreateWithSize()
```
NN_Tensor *OH_NNTensor_CreateWithSize (size_t deviceID, NN_TensorDesc *tensorDesc, size_t size )
```
**Description**
Creates an [NN_Tensor](#nn_tensor) instance based on the specified memory size and [NN_TensorDesc](#nn_tensordesc) instance.
This API uses **size** as the number of bytes of tensor data and allocates device memory to it. The device driver directly obtains tensor data in zero-copy mode.
Note that this API copies **tensorDesc** to [NN_Tensor](#nn_tensor). Therefore, if **tensorDesc** is no longer needed, destroy it by calling [OH_NNTensorDesc_Destroy](#oh_nntensordesc_destroy).
**deviceID** indicates the ID of the selected device. If the value is **0**, the first device is used.
**tensorDesc** is mandatory. If it is a null pointer, an error code is returned. The value of **size** must be greater than or equal to the number of bytes occupied by **tensorDesc**, which can be obtained by calling [OH_NNTensorDesc_GetByteSize](#oh_nntensordesc_getbytesize). Otherwise, an error code is returned. If the tensor shape is dynamic, **size** is not checked.
If the [NN_Tensor](#nn_tensor) instance is no longer needed, destroy it by calling [OH_NNTensor_Destroy](#oh_nntensor_destroy).
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| deviceID | Device ID. If the value is **0**, the first device in the current device list is used by default.|
| tensorDesc | Pointer to the [NN_TensorDesc](#nn_tensordesc) instance.|
| size | Size of the tensor data to be allocated.|
**Returns**
Pointer to the [NN_Tensor](#nn_tensor) instance. If the operation fails, **NULL** is returned.
### OH_NNTensor_Destroy()
```
OH_NN_ReturnCode OH_NNTensor_Destroy (NN_Tensor **tensor)
```
**Description**
Destroys an [NN_Tensor](#nn_tensor) instance.
If the [NN_Tensor](#nn_tensor) instance is no longer needed, call this API to destroy it. Otherwise, memory leak will occur.
If the **tensor** or **\*tensor** pointer is null, this API returns an error code but does not perform the destruction operation.
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| tensor | Level-2 pointer to the [NN_Tensor](#nn_tensor) instance.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNTensor_GetDataBuffer()
```
void *OH_NNTensor_GetDataBuffer (const NN_Tensor *tensor)
```
**Description**
Obtains the memory address of [NN_Tensor](#nn_tensor) data.
You can read/write data from/to tensor data memory. The data memory is mapped from the shared memory on the device. Therefore, the device driver can directly obtain tensor data in zero-copy mode.
Note: Only tensor data in the [offset, size) segment in the corresponding shared memory can be used. **offset** indicates the offset in the shared memory and can be obtained by calling [OH_NNTensor_GetOffset](#oh_nntensor_getoffset). **size** indicates the total size of the shared memory, which can be obtained by calling [OH_NNTensor_GetSize](#oh_nntensor_getsize).
If the **tensor** pointer is null, a null pointer is returned.
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| tensor | Pointer to the [NN_Tensor](#nn_tensor) instance.|
**Returns**
Pointer to the tensor data memory. If the operation fails, a null pointer is returned.
### OH_NNTensor_GetFd()
```
OH_NN_ReturnCode OH_NNTensor_GetFd (const NN_Tensor *tensor, int *fd )
```
**Description**
Obtains the file descriptor of the shared memory where [NN_Tensor](#nn_tensor) data is stored.
**fd** corresponds to a device shared memory and can be used by another [NN_Tensor](#nn_tensor) through [OH_NNTensor_CreateWithFd](#oh_nntensor_createwithfd).
If **tensor** or **fd** pointer is null, an error code is returned.
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| tensor | Pointer to the [NN_Tensor](#nn_tensor) instance.|
| fd | **fd** of the shared memory.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNTensor_GetOffset()
```
OH_NN_ReturnCode OH_NNTensor_GetOffset (const NN_Tensor *tensor, size_t *offset )
```
**Description**
Obtains the offset of [NN_Tensor](#nn_tensor) data in the shared memory.
**offset** indicates the offset of tensor data in the corresponding shared memory. It can be used by another [NN_Tensor](#nn_tensor) together with **fd** and **size** of the shared memory through [OH_NNTensor_CreateWithFd](#oh_nntensor_createwithfd).
Note: Only tensor data in the [offset, size) segment in the shared memory corresponding to the **fd** can be used. **offset** indicates the offset in the shared memory and can be obtained by calling [OH_NNTensor_GetOffset](#oh_nntensor_getoffset). **size** indicates the total size of the shared memory, which can be obtained by calling [OH_NNTensor_GetSize](#oh_nntensor_getsize).
If **tensor** or **offset** pointer is null, an error code is returned.
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| tensor | Pointer to the [NN_Tensor](#nn_tensor) instance.|
| offset | Offset for the fd of the tensor.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNTensor_GetSize()
```
OH_NN_ReturnCode OH_NNTensor_GetSize (const NN_Tensor *tensor, size_t *size )
```
**Description**
Obtains the size of the shared memory where the [NN_Tensor](#nn_tensor) data is stored.
The value of **size** is the same as that of [OH_NNTensor_CreateWithSize](#oh_nntensor_createwithsize) and [OH_NNTensor_CreateWithFd](#oh_nntensor_createwithfd). However, for a tensor created by using [OH_NNTensor_Create](#oh_nntensor_create), the value of **size** is equal to the number of bytes actually occupied by the tensor data, which can be obtained by calling [OH_NNTensorDesc_GetByteSize](#oh_nntensordesc_getbytesize).
Note: Only tensor data in the [offset, size) segment in the shared memory corresponding to the **fd** can be used. **offset** indicates the offset in the shared memory and can be obtained by calling [OH_NNTensor_GetOffset](#oh_nntensor_getoffset). **size** indicates the total size of the shared memory, which can be obtained by calling [OH_NNTensor_GetSize](#oh_nntensor_getsize).
If the **tensor** or **size** pointer is null, an error code is returned.
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| tensor | Pointer to the [NN_Tensor](#nn_tensor) instance.|
| size | Size of the shared memory where the returned data is located.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNTensor_GetTensorDesc()
```
NN_TensorDesc *OH_NNTensor_GetTensorDesc (const NN_Tensor *tensor)
```
**Description**
Obtains an [NN_TensorDesc](#nn_tensordesc) instance of [NN_Tensor](#nn_tensor).
You can use this API to obtain the pointer of the [NN_TensorDesc](#nn_tensordesc) instance of the specified [NN_Tensor](#nn_tensor) instance. You can obtain tensor attributes of various types from the returned [NN_TensorDesc](#nn_tensordesc) instance, such as the name, data format, data type, and shape.
You should not destroy the returned [NN_TensorDesc](#nn_tensordesc) instance because it points to an internal instance of [NN_Tensor](#nn_tensor). Otherwise, once [OH_NNTensor_Destroy](#oh_nntensor_destroy) is called, a crash may occur due to double memory release.
If the **tensor** pointer is null, a null pointer is returned.
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| tensor | Pointer to the [NN_Tensor](#nn_tensor) instance.|
**Returns**
Pointer to the [NN_TensorDesc](#nn_tensordesc) instance. If the operation fails, **NULL** is returned.
### OH_NNTensorDesc_Create()
```
NN_TensorDesc *OH_NNTensorDesc_Create ()
```
**Description**
Creates an [NN_TensorDesc](#nn_tensordesc) instance.
[NN_TensorDesc](#nn_tensordesc) describes various tensor attributes, such as the name, data type, shape, and format.
You can create an [NN_Tensor](#nn_tensor) instance based on the input [NNN_TensorDesc](#nn_tensordesc) instance by calling the following APIs:
[OH_NNTensor_Create](#oh_nntensor_create)
[OH_NNTensor_CreateWithSize](#oh_nntensor_createwithsize)
[OH_NNTensor_CreateWithFd](#oh_nntensor_createwithfd)
Note: This API copies the [NN_TensorDesc](#nn_tensordesc) instance to [NN_Tensor](#nn_tensor). This way, you can create multiple [NN_Tensor](#nn_tensor) instances with the same [NN_TensorDesc](#nn_tensordesc) instance. If the [NN_TensorDesc](#nn_tensordesc) instance is no longer needed, destroy it by calling [OH_NNTensorDesc_Destroy](#oh_nntensordesc_destroy).
**Since**: 11
**Returns**
Pointer to the [NN_TensorDesc](#nn_tensordesc) instance. If the operation fails, **NULL** is returned.
### OH_NNTensorDesc_Destroy()
```
OH_NN_ReturnCode OH_NNTensorDesc_Destroy (NN_TensorDesc **tensorDesc)
```
**Description**
Releases an [NN_TensorDesc](#nn_tensordesc) instance.
If the [NN_TensorDesc](#nn_tensordesc) instance is no longer needed, call this API to destroy it. Otherwise, memory leakage occurs.
If **tensorDesc** or **\*tensorDesc** is a null pointer, an error code is returned but the object will not be destroyed.
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| tensorDesc | Level-2 pointer to the [NN_TensorDesc](#nn_tensordesc) instance.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNTensorDesc_GetByteSize()
```
OH_NN_ReturnCode OH_NNTensorDesc_GetByteSize (const NN_TensorDesc *tensorDesc, size_t *byteSize )
```
**Description**
Obtains the number of bytes occupied by the tensor data obtained through calculation based on the shape and data type of an [NN_TensorDesc](#nn_tensordesc) instance.
The number of bytes occupied by data can be calculated based on the shape and data type of [NN_TensorDesc](#nn_tensordesc) by calling this API.
If the tensor shape is dynamically variable, this API returns an error code and **byteSize** is **0**.
To obtain the number of elements in the tensor data, call [OH_NNTensorDesc_GetElementCount](#oh_nntensordesc_getelementcount).
If **tensorDesc** or **byteSize** is a null pointer, an error code is returned.
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| tensorDesc | Pointer to the [NN_TensorDesc](#nn_tensordesc) instance.|
| byteSize | Size of the returned data, in bytes.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNTensorDesc_GetDataType()
```
OH_NN_ReturnCode OH_NNTensorDesc_GetDataType (const NN_TensorDesc *tensorDesc, OH_NN_DataType *dataType )
```
**Description**
Obtains the data type of an [NN_TensorDesc](#nn_tensordesc) instance.
You can use this API to obtain the data type of a specified [NN_TensorDesc](#nn_tensordesc) instance.
If **tensorDesc** or **dataType** is a null pointer, an error code is returned.
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| tensorDesc | Pointer to the [NN_TensorDesc](#nn_tensordesc) instance.|
| dataType | Tensor data type.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNTensorDesc_GetElementCount()
```
OH_NN_ReturnCode OH_NNTensorDesc_GetElementCount (const NN_TensorDesc *tensorDesc, size_t *elementCount )
```
**Description**
Obtains the number of elements in an [NN_TensorDesc](#nn_tensordesc) instance.
You can use this API to obtain the number of elements in the specified [NN_TensorDesc](#nn_tensordesc) instance. To obtain the size of tensor data, call [OH_NNTensorDesc_GetByteSize](#oh_nntensordesc_getbytesize).
If the tensor shape is dynamically variable, this API returns an error code and **elementCount** is **0**.
If **tensorDesc** or **elementCount** is a null pointer, an error code is returned.
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| tensorDesc | Pointer to the [NN_TensorDesc](#nn_tensordesc) instance.|
| elementCount | Number of elements.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNTensorDesc_GetFormat()
```
OH_NN_ReturnCode OH_NNTensorDesc_GetFormat (const NN_TensorDesc *tensorDesc, OH_NN_Format *format )
```
**Description**
Obtains the data format of an [NN_TensorDesc](#nn_tensordesc) instance.
You can use this API to obtain the data format, that is, [OH_NN_Format](#oh_nn_format, of the specified [NN_TensorDesc](#nn_tensordesc) instance.
If **tensorDesc** or **format** is a null pointer, an error code is returned.
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| tensorDesc | Pointer to the [NN_TensorDesc](#nn_tensordesc) instance.|
| format | Tensor data format.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNTensorDesc_GetName()
```
OH_NN_ReturnCode OH_NNTensorDesc_GetName (const NN_TensorDesc *tensorDesc, const char **name )
```
**Description**
Obtains the name of an [NN_TensorDesc](#nn_tensordesc) instance.
You can use this API to obtain the name of the specified [NN_TensorDesc](#nn_tensordesc) instance. The value of **\*name** is a C-style string ending with **\0**.
If **tensorDesc** or **name** is a null pointer, an error code is returned. As an output parameter, **\*name** must be a null pointer. Otherwise, an error code is returned. For example, you should define **char\* tensorName = NULL** and pass **&tensorName** as a parameter of **name**.
You do not need to release the memory of **name**. When **tensorDesc** is destroyed, it is automatically released.
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| tensorDesc | Pointer to the [NN_TensorDesc](#nn_tensordesc) instance.|
| name | Tensor name.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNTensorDesc_GetShape()
```
OH_NN_ReturnCode OH_NNTensorDesc_GetShape (const NN_TensorDesc *tensorDesc, int32_t **shape, size_t *shapeLength )
```
**Description**
Obtains the shape of an [NN_TensorDesc](#nn_tensordesc) instance.
You can use this API to obtain the shape of the specified [NN_TensorDesc](#nn_tensordesc) instance.
If **tensorDesc**, **shape**, or **shapeLength** is a null pointer, an error code is returned. As an output parameter, **\*shape** must be a null pointer. Otherwise, an error code is returned. For example, you should define **int32_t\* tensorShape = NULL** and pass **&tensorShape** as a parameter of **shape**.
You do not need to release the memory of **shape**. When **tensorDesc** is destroyed, it is automatically released.
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| tensorDesc | Pointer to the [NN_TensorDesc](#nn_tensordesc) instance.|
| shape | List of tensor shapes.|
| shapeLength | Length of the list of tensor shapes.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNTensorDesc_SetDataType()
```
OH_NN_ReturnCode OH_NNTensorDesc_SetDataType (NN_TensorDesc *tensorDesc, OH_NN_DataType dataType )
```
**Description**
Sets the data type of an [NN_TensorDesc](#nn_tensordesc) instance.
After an [NN_TensorDesc](#nn_tensordesc) instance is created, call this API to set the tensor data type.
If **tensorDesc** is a null pointer, an error code is returned.
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| tensorDesc | Pointer to the [NN_TensorDesc](#nn_tensordesc) instance.|
| dataType | Tensor data type to be set.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNTensorDesc_SetFormat()
```
OH_NN_ReturnCode OH_NNTensorDesc_SetFormat (NN_TensorDesc *tensorDesc, OH_NN_Format format )
```
**Description**
Sets the data format of an [NN_TensorDesc](#nn_tensordesc) instance.
After an [NN_TensorDesc](#nn_tensordesc) instance is created, call this API to set the data format of the tensor.
If **tensorDesc** is a null pointer, an error code is returned.
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| tensorDesc | Pointer to the [NN_TensorDesc](#nn_tensordesc) instance.|
| format | Tensor data format to be set.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNTensorDesc_SetName()
```
OH_NN_ReturnCode OH_NNTensorDesc_SetName (NN_TensorDesc *tensorDesc, const char *name )
```
**Description**
Sets the name of an [NN_TensorDesc](#nn_tensordesc) instance.
After an [NN_TensorDesc](#nn_tensordesc) instance is created, call this API to set the tensor name. The value of **\*name** is a C-style string ending with **\0**.
If **tensorDesc** or **name** is a null pointer, an error code is returned.
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| tensorDesc | Pointer to the [NN_TensorDesc](#nn_tensordesc) instance.|
| name | Name of the tensor to be set.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).
### OH_NNTensorDesc_SetShape()
```
OH_NN_ReturnCode OH_NNTensorDesc_SetShape (NN_TensorDesc *tensorDesc, const int32_t *shape, size_t shapeLength )
```
**Description**
Sets the data shape of an [NN_TensorDesc](#nn_tensordesc) instance.
After an [NN_TensorDesc](#nn_tensordesc) instance is created, call this API to set the tensor shape.
If **tensorDesc** or **shape** is a null pointer or **shapeLength** is **0**, an error code is returned.
**Since**: 11
**Parameters**
| Name| Description|
| -------- | -------- |
| tensorDesc | Pointer to the [NN_TensorDesc](#nn_tensordesc) instance.|
| shape | List of tensor shapes to be set.|
| shapeLength | Length of the list of tensor shapes.|
**Returns**
Execution result of the function. If the operation is successful, **OH_NN_SUCCESS** is returned. If the operation fails, an error code is returned. For details about the error codes, see [OH_NN_ReturnCode](#oh_nn_returncode).